
By Aaron Tay, Head, Data Services
Summary: arXiv will now ban authors for a year if their papers show clear signs of unchecked AI output, including hallucinated references. Fabricated citations are becoming more common across the literature. This raises an important question: do dedicated academic search tools such as Consensus, Undermind, and Elicit also generate false references? Both the existing literature and my own test of 100 references show they almost never do compared to chatbots, because they retrieve real papers and use code, not the model, to verify every citation. What remains is subtler: minor metadata errors inherited from the source index, and real papers cited for claims they do not support.
arXiv threatens one year ban for authors who use LLM for research but do not properly check the manuscript before depositing
arXiv has recently clarified that authors may face a one-year submission ban. The trigger is "incontrovertible evidence" that they failed to check LLM-generated content.
The examples given include hallucinated references, AI-generated meta-comments left in the text, and placeholder data never replaced with real results. After the ban, any further arXiv submission must first be accepted at a peer-reviewed venue. Rather than banning AI tools, arXiv is reinforcing one principle: authors remain fully responsible for everything they submit, whatever part AI generated or assisted.
The clarification came from Thomas G. Dietterich, currently chair of arXiv's Computer Science Section. He posted it in a thread on X, not on a formal page on the arXiv site. Still, it is more than an offhand post. Dietterich set out the policy in an interview with Nature too, so researchers should treat it as real.
Fabricated references are already leading to corrections and retractions
This is not just a future arXiv risk. Papers and books have already been flagged, corrected, removed, or retracted because their reference lists included fabricated or unverifiable sources. Retraction Watch, for example, reported a Springer Nature machine-learning book that was retracted after the publisher could not verify 25 of its 46 references; the retraction notice stated that the publisher no longer had confidence in the reliability of the book. Retraction Watch has also covered journal articles with nonexistent references, including a Springer Nature article where 12 of 14 references reportedly did not exist and was retracted.
The problem can also cascade. A researcher may cite a paper that appears legitimate, only for that paper to be corrected or retracted later because its own references were fabricated. If the later researcher relied on that paper’s claims without checking the underlying evidence, the error has already moved downstream. This is particularly risky in reviews and evidence syntheses, where one unreliable paper can be repeatedly summarised, cited, and built into a field’s apparent consensus.
Fabricated references are no longer just a student problem
The scale of the problem is now well documented and appears to be worsening. Zhao et al. (2026) audited 111 million references across 2.5 million papers on arXiv, bioRxiv, SSRN and PubMed Central. They estimated, conservatively, 146,932 hallucinated citations in 2025 alone, with the rise concentrated after widespread LLM adoption.
In the biomedical literature, a Lancet correspondence by Topaz et al. (2026) screened roughly 2.5 million open-access papers in PubMed Central. The authors tried to verify 97.1 million of their references with PMIDs.
The study identified 4,046 fabricated references across 2,810 papers. The proportion of papers with at least one fabricated reference rose from about 1 in 2,828 in 2023 to 1 in 458 in 2025 and 1 in 277 in the first seven weeks of 2026. Separately, when measured as fabricated references per 10,000 papers, the fabrication rate rose more than twelvefold, from about 4 per 10,000 papers in 2023 to 51.3 per 10,000 in the fourth quarter of 2025, and 56.9 per 10,000 in early 2026.
GhostCite (2026) analysed 2.2 million citations from 56,381 papers at top-tier AI, machine-learning and security venues from 2020 to 2025, and found that 1.07 per cent of papers contained invalid or fabricated citations, an 80.9 per cent jump in 2025. Its survey of 97 researchers exposed a verification gap, with 41.5 per cent copy-pasting BibTeX without checking it.
A separate study of ACL, NAACL and EMNLP papers from 2024 to 2025 by Sakai, Kamigaito & Watanabe (2026) reported nearly 300 papers with at least one hallucinated citation, almost all of them in 2025, with half of them from EMNLP 2025 the most recent conference in the dataset.
Chatbots or Search Engines?
One distinction matters before going further. Almost all of these fabrications come from researchers prompting general-purpose chatbots, which do not look up references but synthesise plausible-looking ones from patterns in their training data. The Lancet authors suggest that uncritical use of AI writing tools is one possible contributor to the rise and GhostCite makes a similar point about standard LLM prompting: when asked for citations without a retrieval mechanism, models tend to generate plausible references rather than look them up.
That raises a separate question about a different class of tool. Specialised academic AI search systems such as Consensus, Undermind, Elicit, Scite Assistant and SciSpace retrieve real papers and then cite them. Do they fabricate references too, or does retrieval protect against this absolutely?
Here is the short version, before the evidence. Across the literature, my own test, and how these tools are built, the dedicated academic search tools almost never invent a reference. What survives in the academic tools are two smaller risks: minor metadata errors inherited from the source index, which are not hallucinations, and the harder problem of a real, correctly retrieved paper being cited for a claim it does not support. So a verified citation proves a paper exists. It does not prove the paper supports the sentence it sits in. That last check stays with you, whichever tool you used.
Two main types of hallucinations in citations
It helps to separate two kinds of citation problems we see with LLMs.
First, ghost or fabricated references. These are citations to works that do not exist, or that stitch real-looking authors, titles, journals, years, DOIs or URLs into a false bibliographic object. This is the problem arXiv is most clearly targeting. A reference with a minor error, such as a slightly wrong publication year, is not a ghost reference. That usually reflects a defect in the source metadata, for example Google Scholar merging versions of a work, or an error extracting metadata from the PDF.
Second, real references that do not support the claim. This is sometimes known as citation/source faithfulness. Here the paper exists, but it is misread, over-interpreted, cited for a stronger claim than it supports, or used as evidence for something it never studied. This is harder to detect. A DOI or database match can tell us a paper is real. It cannot tell us that the cited paper supports the sentence it sits in.
Consensus draws a similar line between misread sources and fake sources, and claims only the first kind of error is possible with its tool. Scite Assistant, Undermind and Elicit make the same claim, explicitly or implicitly. But is it true? I will approach the question from three angles.
What does the literature say?
There is a large literature showing that prompting ChatGPT, Gemini or Claude directly for references often produces fabrications. There is far less testing of academic AI search engines specifically.
Aljamaan et al.(2024) found that, unlike Perplexity, Bing and ChatGPT, the dedicated tools Elicit and SciSpace produced essentially no fabricated references, though both showed minor errors in publication date and sometimes returned real papers that were not relevant to the prompt, which is a different failure.
Work in a master’s thesis by Preisler(2024) comparing Scopus AI, Elicit, SciSpace and Scite in business administration reached the same conclusion:
"While some references had minor inaccuracies in their bibliographic details, none were entirely fabricated or nonexistent. This suggests that the frequency of ghost references or hallucinations in both SciSpace and Elicit's generated reference lists is negligible."
This evidence points one way, but it is thin and dated. A single study and a thesis cannot settle the question, and the tools have moved on since. My own test below is smaller still, but more current.
A real-world test of Consensus and Undermind
Today, there are many free and paid services that scan reference lists for fabrications e.g. (citeMe, CheckIfExist (also open source), citeTrue, Sourcely etc). If you do not want to upload to a remote site, there are ones you can run locally and are mostly open source including RefChecker by Mark Russinovich, Hallucinated Reference Finder, UB Mannheim check-fake-references, citescan, hallucitechecker etc,
Many are also available as MCP servers (mostly local not remote), there’s even one packaged as a Claude Code Skill!
Note: I have not tried most of them, so try them at your own risk.
They all work basically the same way, you upload your reference list in RIS, BibTex, Csv and it checks against various open sources of scholarly metadata like CrossRef, Semantic Scholar, OpenAlex, DBLP, ArxiV etc for mismatches.
For this test I used the Scholar Sidekick service. There is nothing special about the tool.
It checks whether a reference is bibliographically real and internally consistent, by taking an identifier such as a DOI, PMID, PMCID, arXiv ID, ISBN, ISSN, NASA ADS bibcode or WHO IRIS URL, resolving it against authoritative registries, and comparing the returned metadata against the supplied citation, especially title, first author, year and container title. See this for more details.

You can try it yourself using the web form or use the API.
To be clear about scope, this is a small, informal probe and not a systematic audit. I extracted 100 references in total, 50 from Consensus - Deep Search and top 50 in Undermind reports, and ran each through the API with a single verifier.
Of the 100, 93 resolved to a confident match, 14 of those with minor metadata errors, mostly publication year or container mismatch such as journal or preprint, all plausibly explained by different versions of the same work. The remaining 7 were flagged as particularly suspicious for review, 2 from Consensus and 5 from Undermind.
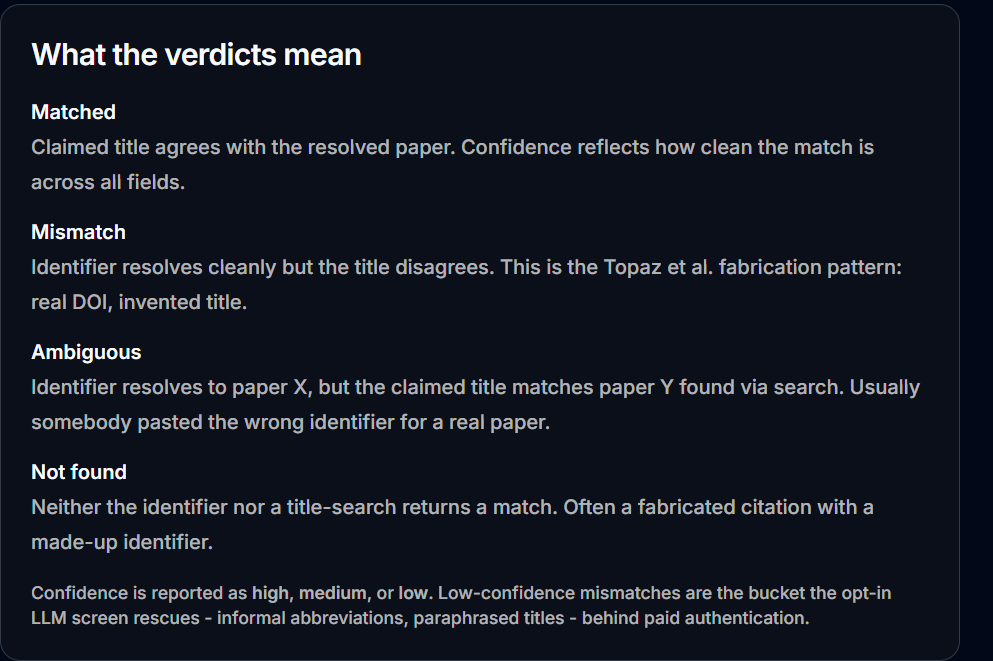
On manual examination, none of the seven flagged records is a fabricated, non-existent reference. Every one resolves to a real, identifiable work
The flags seem to be for metadata defects of four kinds.
The most common is version-title drift, where the same study is indexed under a different version title than the verifier resolved, with the same DOI or the same author lineage but a different label.
Next are missing DOIs, where with no identifier the verifier falls back to title-only matching, which for obvious reasons produced the low-confidence and not-found verdicts.
All three of Undermind's worst cases had blank DOIs. Then there is field-level metadata noise, a real paper with an exact or near-exact title, but a wrong first author, often a name-formatting artefact, or a wrong year or container.
Last is title mangling, a dropped or altered word, such as "Cite Unseen" exported as "Unseen".
In summary, the finding is consistent with the 2024 literature. Across this sample, neither tool fabricated a reference, though you do get some metadata errors.
How do RAG tools prevent fabricated references
Most of these tools use retrieval-augmented generation, or RAG. At its simplest, the system uses your input to search for relevant papers, returns the top results, and prompts a language model to answer the query using what was found and to cite it.
In the diagram above, we assume the source search or preindexed is OpenAlex.
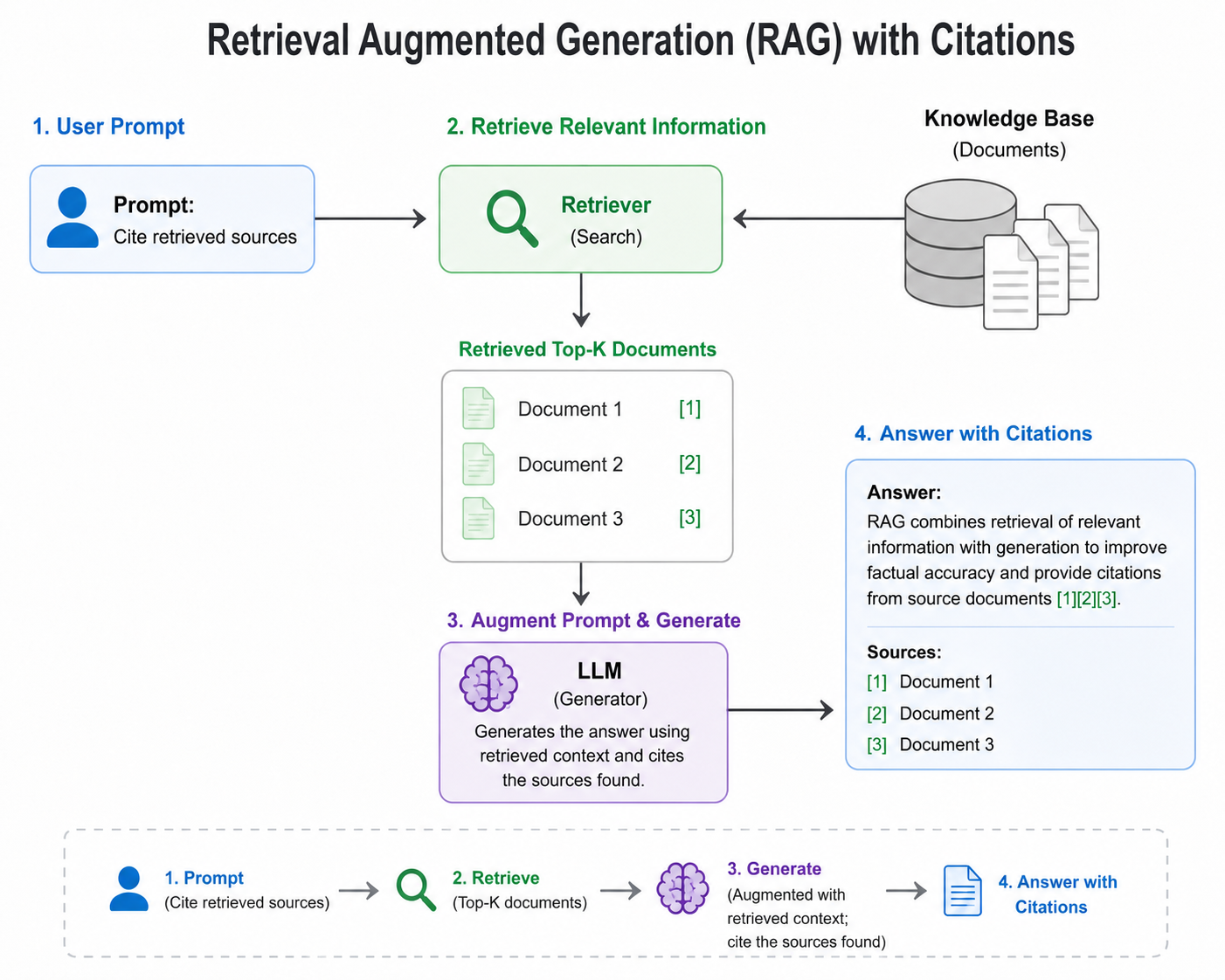
The obvious worry is that language models are non-deterministic. What stops the model from ignoring the instruction to cite properly what was retrieved?
Here are some LLM possible failure modes
- Fabricated paper: the cited paper does not exist.
- Unretrieved existing paper: the cited paper exists in OpenAlex/the index, but it was not retrieved for this query.
- Misdescribed retrieved paper: the cited paper was retrieved, but the LLM attributes the wrong claim to it.
- Uncited answer: the LLM answers from memory/training data without citations.
By using code to constrain the LLM, it is relatively easy to handle the first two problems with near 100% reliability.
The key point is that while the model is non-deterministic, code is not. After generation, the system can use code, not the model, to check the output. The model can never be assumed 100% reliable no matter how you prompt, but Code-side validation is deterministic and far easier to audit than model behaviour and it can make citation-ID checking highly reliable assuming it is implemented correctly.
There are many ways to do this, but the image below shows one way.
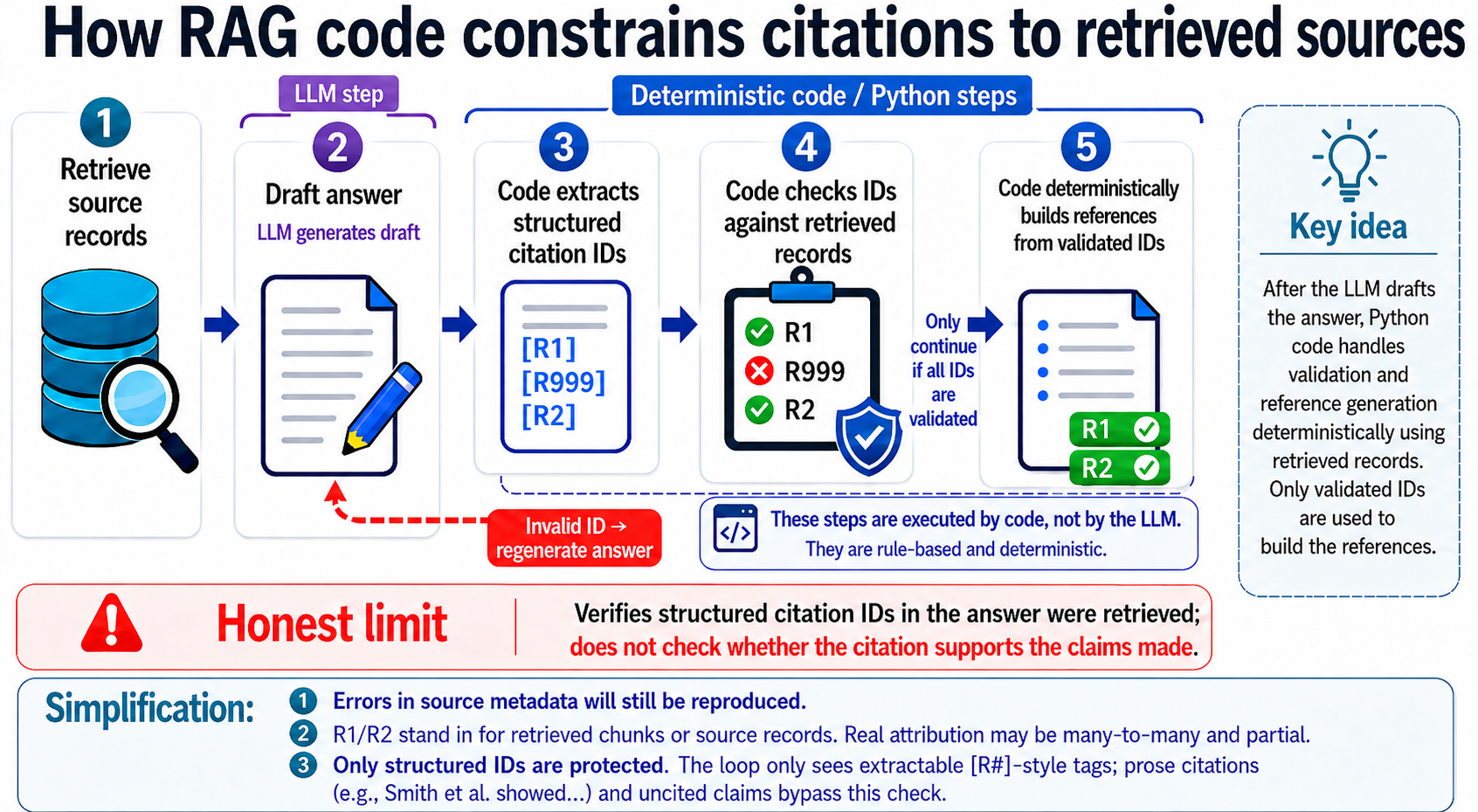
In step one, the system retrieves records from a source such as OpenAlex and labels them [R1], [R2] and so on. Or it could be prelabeled during indexing.
In step two, the model drafts an answer such as "Retrieval-augmented generation was first introduced in 2020 [R1]", just using the LLM as seen earlier.
In step three, a script checks every tag in the draft against the retrieved set to confirm a match. If they pass, step four uses code, again not the model, to add links, references and overlays. If they fail, the LLM will be prompted to generate again. Because steps three and four are code, they always run.
A similar design appears to underlie the verified citation interfaces used by tools such as Undermind, Consensus and Scite, although the exact implementation details differ and are not always publicly documented.


What this verification does not protect against
The check guarantees that any cited reference came from the retrieval step and is therefore “real” (assuming the source is reliable of course). It is not bullet-proof against two further problems.
First, it assumes the source index has accurate metadata and is not polluted with fake records. As LLMs generate more and more fake papers and references, if a source like Semantic Scholar or OpenAlex accidentally crawls and ingests such data, all bets are off.
As it is, many systems, including Undermind and Consensus, draw on sources such as Semantic Scholar. Those sources carry imperfect metadata, the result of parsing errors and aggregation from other databases. As the tests (both by me and in the literature) above showed, this produces references with small errors in title, author or year. These are not hallucinations. The error originates in the source, not the model. It is the same as clicking "Cite" in Google Scholar and getting a slightly wrong reference because the scraped metadata is off, or because two versions have been merged.
I recently saw an Undermind reference that returned a 404 when clicked. That was almost certainly an existing error in the source record, not fabrication.
Second, the answer can cite a real paper that was genuinely retrieved and still misrepresent it.
Verification confirms that a cited paper was retrieved; it says nothing about whether the model used it accurately. A model may tag a passage [R1] while the reasoning was actually drawn from [R2], which was also in the retrieved set. That mismatch can be caught with additional validation. What is harder to detect is a subtler failure: when the model correctly cites [R1] but misreads or overstates what the paper actually says.
Methods such as Natural Language Inference (NLI)-style entailment checking and LLM-as-judge and doing checks at the citation statement/claim level can reduce this risk, but there is no fool-proof way to guarantee a summary is 100% faithful to the source.
A few emerging tools now attempt the harder task of citation support checking rather than merely reference existence checking. SemanticCite, for example, classifies claim-citation pairs as supported, partially supported, unsupported, or uncertain using full-text analysis.
What researchers should know
So, is the tools' claim true? Broadly yes, for the narrow question. Retrieval plus code-side citation validation can largely eliminate one common route to non-existent references: the model inventing citations during generation, which is why the dedicated academic tools do not behave like a raw chatbot. What remains are two residual risks that no verification step removes: small metadata errors inherited from the source index, which are not hallucinations, and misrepresentation of real papers, which a citation check cannot catch.
That is the practical takeaway, and it loops back to arXiv. A verified citation proves a paper exists. It does not prove the paper supports the sentence it is attached to. Whether you used a chatbot, a RAG tool or your own reading, the responsibility for checking that your references are real, and that they say what you claim, stays with you.
