
By Dong Danping, Senior Librarian, Research Services
In today's data-driven world, researchers across various disciplines often find themselves tasked with handling personal data for their research. It also comes with the responsibility to safeguard the privacy of human participants and adhere to legal and regulatory standards such as PDPA, GDPR, or IRB. Furthermore, there is a growing trend among researchers to share or publish their data, sometimes mandated by publishers, funders, or institutions, which requires data to be anonymized beforehand.
In this article, we will discuss the fundamentals of data anonymization, equipping you with the knowledge and skills necessary to prepare your data for sharing with collaborators or publication on a data repository. We will also introduce you to Amnesia, an open-source data anonymization tool. For more in-depth discussion, watch our full library bite-size workshop “Data Anonymization 101 for Researchers”.
Data anonymization refers to the process of modifying data to make it impossible to identify an individual in a dataset, while maintaining the utility of the data for analysis as much as possible. It’s helpful to distinguish with a potentially confusing term, de-identification, which refers to the removal of direct identifiers such as name or NRIC. However, de-identification alone does not suffice to prevent re-identification, which is the ultimate goal of anonymization. To help you navigate the basic concepts, we've provided a table introducing some fundamental terms:
| Direct Identifiers | Indirect identifier | Target attributes | |
|---|---|---|---|
| Definition | Information which is sufficient on its own to identify an individual | Information that is not unique to an individual, but may be used to identify a person when linked with other available information | Data that contributes to the main utility of the dataset. May result in adverse effects when disclosed |
| Examples |
|
|
|
| What needs to be done? | De-identification refers to the removal of direct identifiers, which is usually the first step for anonymization. Information which is sufficient on its own to identify an individual | Indirect identifiers can either be removed entirely or modified using various anonymization techniques, to reduce the possibility of reidentification | Target attributes may be indirect identifiers and sometimes need to go through anonymization too |
Common techniques for anonymization
When dealing with indirect identifiers which may potentially reveal the identity of an individual, it is often helpful to consider various anonymization techniques to mitigate the risk of reidentification or to meet the criteria of privacy models such as k-anonymity.
- Suppression
Removal of variables (aka data columns), observations (aka data rows), or specific values that may pose privacy risks
Example: remove outliers, delete high-risk variables or records, delete free-text entry - Character masking
Replace appropriate characters with a chosen symbol, e.g 192.168.19.5 → 192.168.xx.xx - Categorization
Recode a variable to reduce the granularity and detail in the data. For example, an age variable could be recoded into broader ranges like "30-39," "40-49," and so on, and top-code or bottom code extreme ends as ">70" or “<18”. - Data perturbation
Common techniques include adding random noise to variables, replacing data with simulated values, data shuffling and rounding of variables
When applying any technique to a dataset, one should always be aware of the implications and impacts of that particular technique. For instance, removing an observation can affect multiple variables, or categorizing a continuous variable may significantly limit the ability to draw precise statistical conclusions.
Careful planning and considerations are needed to balance the trade-off between data utility and anonymity.
k-anonymity
k-anonymity is most common privacy model used by researchers as a risk threshold and guideline for anonymization. It is basically about hiding your data in a crowd of k similar data points. Imagine you have a dataset that contains age and ethnicity as indirect identifiers, If you want to achieve k-anonymity of 5, you need to make sure that at least 5 people share the same age + ethnicity combination so that you can’t single out one individual.
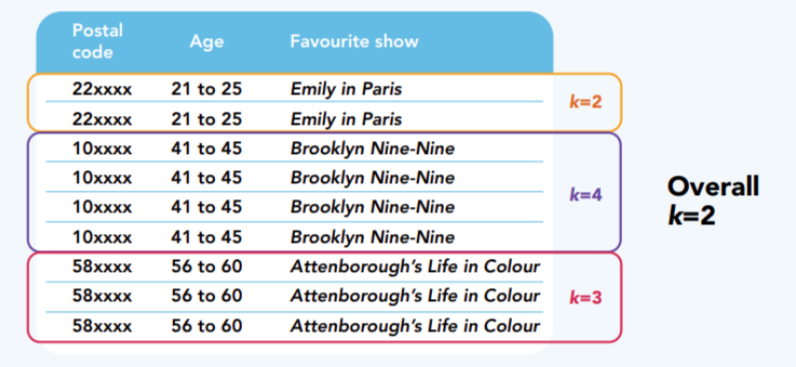
There isn’t a universal k-value that can fit the privacy need of every scenario, but a commonly recommended range is 3-5.
k-anonymity may not be suitable for all types of data or more complex cases. You may need to consider adopting other privacy models such as I-diversity or t-closeness.
Amnesia: A quick start guide
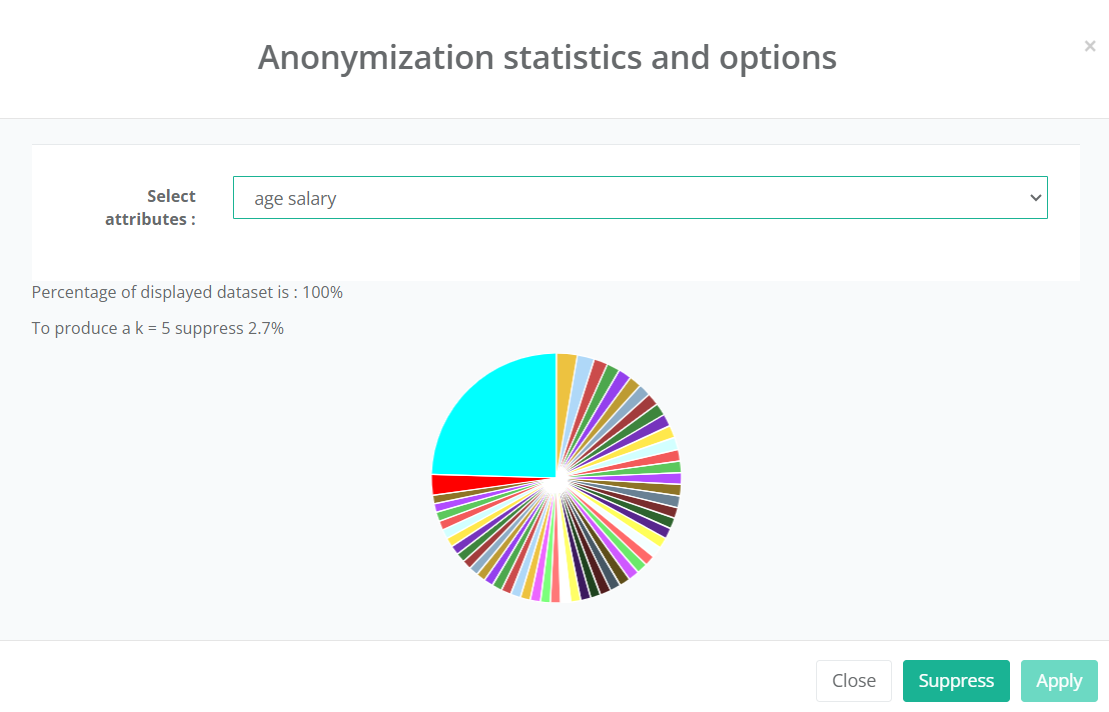
Amnesia Anonymization tool is an open-source tool supported by OpenAIRE. It has a visual and friendly user interface offering features including k-anonymity, km-anonymity and character masking. You can download and install the software and some sample datasets to start playing. Watch the workshop recording from 44:01 onwards for a demo of Amnesia.
Notable features of Amnesia:
- Character-masking for text fields such as email, zip code, etc
- Achieve desired k-anonymity through techniques such as suppression and categorization
- Define hierarchy rules for categorization and explore generated solutions to find one with best trade-off between privacy and utility
- Export anonymized dataset
There are a few other tools developed for the purpose of research data anonymization, such as ARX, µ-Argus and sdcMicro, which are all open and free to download and use. If you have qualitative data such as interview transcripts, instead of go through the tedious process of manual editing, you may want to try textwash, an automated text anonymization tool written in Python, which can automatically remove potentially identity-revealing entities such as personal names or organization names.
Contact Danping (dpdong@smu.edu.sg) if you have any questions about data anonymization or depositing data to SMU Research Data Repository!