
By Aaron Tay, Head, Data Services
In November, we introduced our webinar series on research impact beyond traditional metrics. This series included:
We conclude the series with OpenAlex's Kyle Demes (recording here) sharing about OpenAlex.
What is OpenAlex?
The name OpenAlex comes from the Library of Alexandria and, like its historical precedent, it has a lofty goal of becoming the biggest source of academic data.
Kyle positions OpenAlex as a Scientific Knowledge Graph (SKG), similar to Scopus and Web of Science, as it links papers, authors, institutions and more together. However, it is considerably broader than Scopus or Web of Science.

To get a sense of OpenAlex's scale, this lists the main entities in OpenAlex and what they cover.
Scale and coverage
In terms of size, after the latest November 2025 Walden update—which went beyond just works with Crossref DOIs to now include datasets, software, and other research objects from DataCite and thousands of repositories—they index over 464 million "works", making them the largest single source of academic works, possibly matched only by Google Scholar. For some context, Scopus Index has around 90 million works. (The additional works sum to around 192 million but have poorer quality metadata; you can choose to include them by enabling the Xpac pack.)
That said, they demonstrated a study where, when you restrict OpenAlex to the same set of journals in Scopus and then run the same analysis between this reduced set in OpenAlex versus Scopus, you get essentially a correlation of 1 with the actual Scopus dataset
Openness and access
OpenAlex is extremely open. You can gain access via API, the web interface, and data dumps (available CC0).
The terms of use for the API are also quite generous. At the time of the recording, you get 100,000 API calls (maximum 200 responses per call) daily for free and does not require a API key. (Note: As of 2026, you may soon need to use a free API Key, and limits might be reduced)
Not only is OpenAlex open data, even the code used by OpenAlex is freely available. This allows full transparency on, for example, how OpenAlex clusters papers into topics (see the github repo).
Use cases and adoption
Kyle showed numerous examples of databases created by libraries and research offices around the world using OpenAlex data. The main story here was how, because OpenAlex is open and easy to use, many institutions defaulted to using it rather than proprietary data like Scopus or Web of Science, which may not grant the rights to do what they wanted.
Similarly, he discussed the popular science mapping tool VOSviewer (see our coverage) and noted the advantages using open data brought. Unlike using Scopus and Web of Science—where you must first log in to Scopus, run the search, export and import into VOSviewer—with OpenAlex, you can simply pull the data into VOSviewer directly through the open API. Many other similar science mapping tools also use OpenAlex as one of their sources.
University rankings are starting to use OpenAlex data. Besides the FT Research Insights ranking, it is also used in the Leiden Ranking Open Edition. (See our coverage)
Lastly, many of the other speakers in earlier talks of this series, such as Overton and Open Syllabus, shared that they also used OpenAlex data for various purposes, which supports Kyle's point about OpenAlex wanting to be the foundation upon which other services are built.
Lastly, University rankings are starting to use OpenAlex data. Besides the FT Research Insights ranking, it is also used in the Leiden Ranking Open Edition.
Web interface demonstration
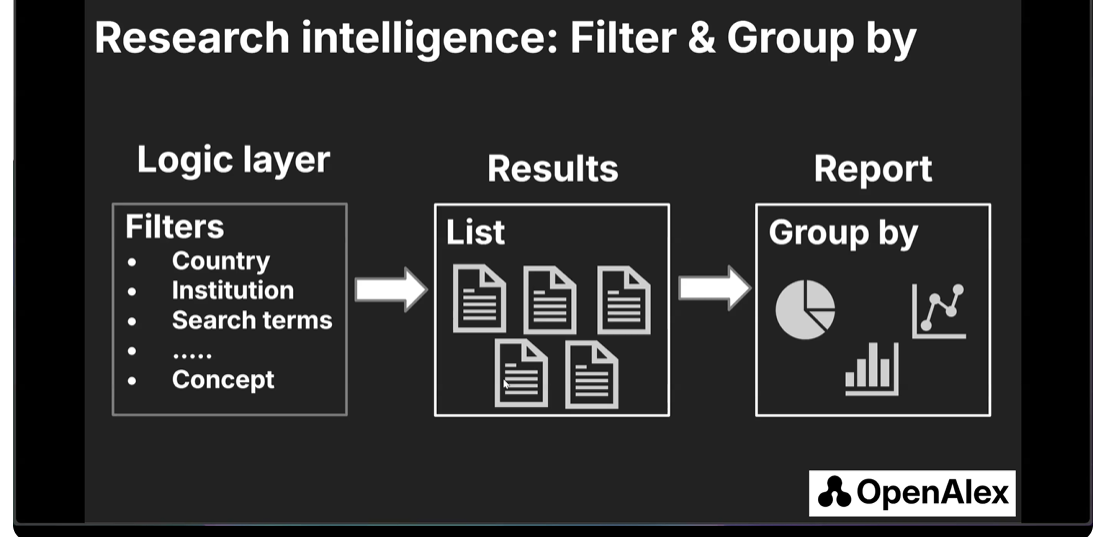
Kyle then demonstrated the OpenAlex web interface where you could use simple logic like filters, excludes and groupby functions to slice and dice to your heart's content.
He shared that filters like work is "indexed in DOAJ" and work is in "CWTS Core source" serve as ways to filter to higher-quality journals. You can also filter by OpenAlex's topic hierarchy from Domains (4), to Fields (26), Subfields (252), to Topics (4,516).
In particular, you can manually set up a filter to include only journals/sources that you are interested in. Kyle shared this was how FT created their Research Insights rankings.
Field-Weighted Citation Impact (FWCI)
He also discussed how Field-Weighted Citation Impact (FWCI) was used by FT and one of the reasons why they implemented it.
I also asked how similar or different FWCI is from the FWCI calculated in Scopus/SciVal. The answer was it is very similar, with the same formula, but with the following differences:
In Scopus, FWCI normalises by subject using ASJC (All Science Journal Classification), while OpenAlex uses the somewhat equivalent subfields. The main difference here is that ASJC classifies all articles in the same journal to the same ASJC category, while OpenAlex analyses the title and abstract of each work to do the assignment.
The other major difference stems from the fact that OpenAlex's index is more inclusive than Scopus. As such, a higher percentage of OpenAlex-indexed works have zero citations due to the nature of the index. This drives down the average expected citation values so that works that do get cited are likely to have higher FWCI values in OpenAlex.
Metadata quality and challenges
There was a discussion about the relative metadata quality between Scopus/Web of Science and OpenAlex. It was mentioned that part of this could be due to the fact that many librarians and researchers spend effort helping to curate and clean up Scopus/WoS metadata, compared to the relatively unknown OpenAlex, as well as the fact that, by the nature of OpenAlex's indexed works, many items naturally don't have affiliations. For example, a monograph from the social sciences would often have a biography of the author and yet not state the affiliation anywhere.
At the time of the recording, they were planning a way for individual authors to curate their papers, and even a way for institutions to work as a whole.
Additional note: As of 2026, they offer to OpenAlex institutional members (1,000 USD annually), among other benefits the right to edit the affiliation string matching rules for your institution.
In terms of metadata from publishers, there was also a discussion on how two publishers have asked OpenAlex to take down abstracts from non-open publications. Unfortunately, there is as yet no consensus on whether abstracts count as metadata or not and hence whether they can be copyrighted.
Kyle also shared that some publishers are withholding affiliation data from being made available because they want to provide a value-added service to institution
Conclusion
OpenAlex represents a significant development in open research infrastructure. Its scale—now exceeding 464 million works—combined with its liberal access terms and transparent methodology makes it an increasingly viable alternative to proprietary databases for many use cases.
The platform's openness has practical implications: institutions can build custom databases without licensing constraints, integrate data directly into tools like VOSviewer, and access the underlying code to understand exactly how metrics are calculated. This transparency is particularly valuable for research evaluation, where understanding the methodology behind citation metrics is crucial.
As an aside, OpenAlex's openness is such that you can make a frontier LLM like Claude or Gemini, vibe code the analysis you want!
Below shows an example
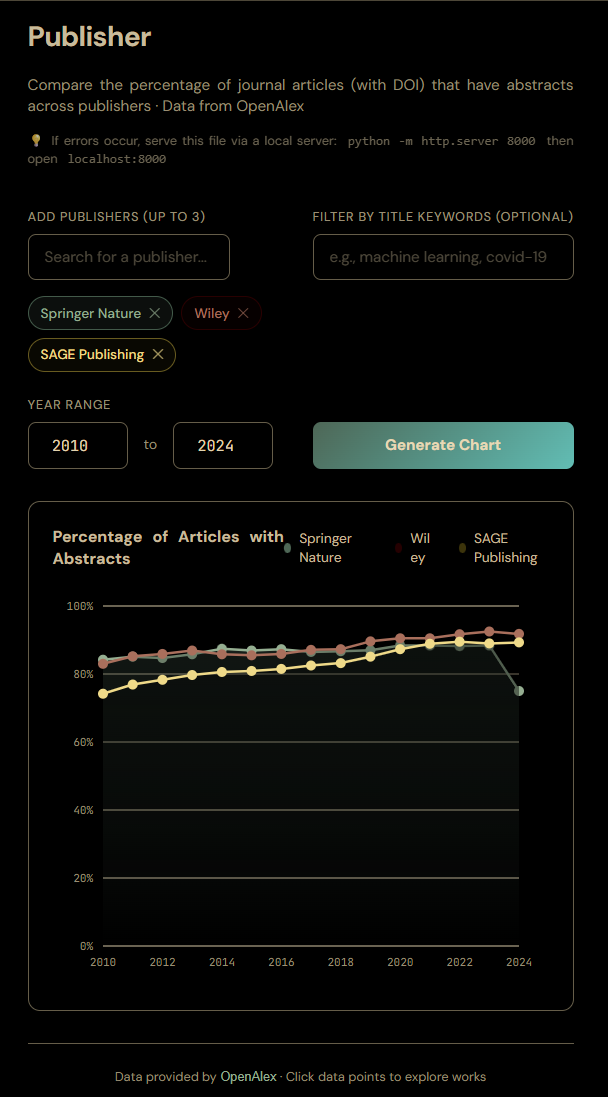
For example, I easily vibed coded a interactive web demo with just a few prompts that allowed me to enter up to 3 publishers and it would plot % of works where abstracts were available. Clicking on each point, brings you to the OpenAlex results page, shows all the works that match the plotted point. (Here's an example)
However, trade-offs remain. Whilst OpenAlex's inclusiveness is a strength, it brings challenges around metadata quality and completeness, particularly for affiliation data and non-journal content. The ongoing tension with some publishers over abstract and affiliation data also highlights the broader politics of open research infrastructure.
For researchers and research support professionals at SMU, OpenAlex is worth exploring—particularly for bibliometric analyses, science mapping, and situations where proprietary database licences restrict what you can do with the data. Its growing adoption as the foundation for other services (rankings, policy tracking tools, educational platforms) suggests it will continue to shape the landscape of research intelligence.
The full recording provides additional detail on specific features and use cases that may be relevant to your work.
