
By Aaron Tay, Lead, Data Services
In this series, Aaron provides an overview of some of the cutting edge tools for research that have been released recently.
Bibfix – Improve the quality of your bibliographic data files
In the companion piece this month, I provided an overview of CitationChaser (insert link to Citation Chaser piece), an open-source tool to assist with forward and backward citation searching from multiple records.
But this isn’t the only open-source tool created by Neal Haddaway to assist with literature review and systematic reviews.
As part of the Evidence Synthesis Hackathon, he also recently completed a tool Bibfix, which helps you fix missing data from bibliographic files.
Like CitationChaser this tool is an open-source R package with an easy to use interface via a shiny app.
For most users, you want to access it via https://estech.shinyapps.io/bibfix/.
Say for example, you have a list of records extracted from a database or tool in RIS format. Or you have a set of records in your reference manager of choice say Zotero. Depending on the source of your records the quality might differ with missing fields.
In the example below, I uploaded a sample RIS file and Bibfix provides an analysis of the completeness of 10 important fields.
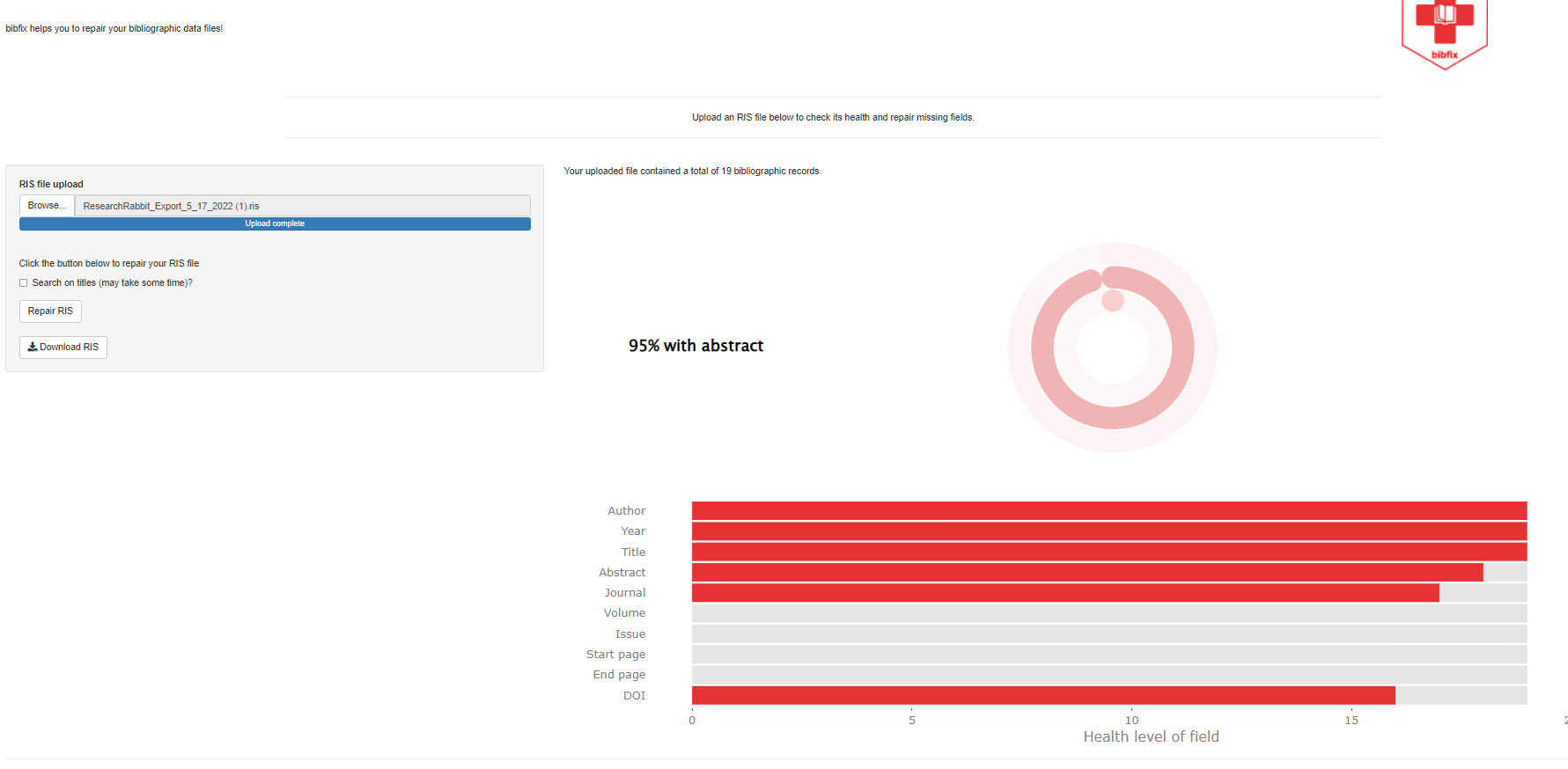
The analysis shown that out of 19 records, the fields “author”, “title” and “year of publication” are near 100% complete. But the field “abstracts” is at 95% complete and there are no values for fields like “volume”, “issue”, “starting page” for all the records. As such, there are no complete records.
Click on “Repair RIS” and Bibfix uses Lens.org and OpenAlex to look for matches by DOI and replaces the missing values with what it can find from the Lens.org and OpenAlex indexes.
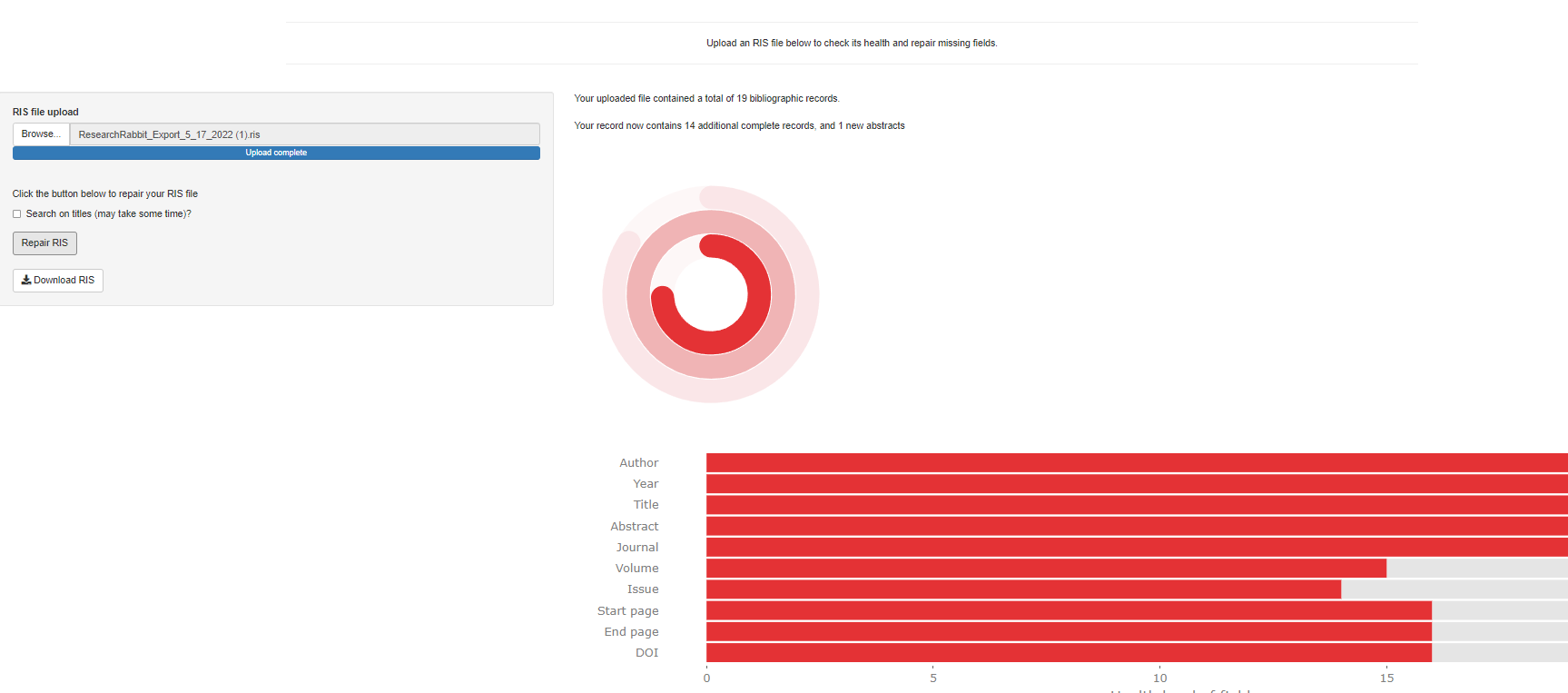
After repair, the file has 14 additional complete records (mostly due to addition of fields on doi, issue, volume and starting page). There is also one additional abstract added.
You can then export this “Repaired” bibliographic file into RIS for use.
Librarian’s Take: This is a very useful tool for cleaning up bibliographic records with the following points to take note. Currently Bibfix only replaces empty fields and never replaces a field that already has a value. This means it will correct only omissions in the metadata field and not errors in the data. Secondly, the sources of data that Bibfix draws on to replace empty fields is from Lens.org and OpenAlex . Like any source, these sources are not perfect and might have errors in them. Because this is a very new tool, it pays to check the results to see if it makes sense. I have found cases where it totally fails to recognize valid entries in the Journal field from databases output like Scopus and Web of Science
PRISMA2020 flow chart maker
So far in this issue we have showcased two Neal Haddaway’s tools to assist with systematic reviews , CitationChaser and Bibfix. Here we introduce a third tool PRISMA2020 , a simple tool that allows you to create flowcharts compliant with PRISMA2020.
When doing a systematic review or meta-analysis besides a conducting standard like the Cochrane Handbook for Systematic Reviews of Interventions, guidelines from the Campbell Collaboration (social interventions), many reviews also follow the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) to standardise reporting details. As noted in the ResearchRadar piece "What to include in your systematic review or meta-analyses report? PRISMA has an updated checklist", this standard has been updated to a 2020 version.
A central piece of the PRISMA reporting standard is the production of a flow chart showing systematic filtering and screening of records until the included studies are left.
You can always create the flowchart yourself but Neal Haddaway has kindly created PRISMA2020 to make this easy.
As always, it is available in a R package and Shiny package and you can use this easily to customize the flow chart to your heart’s content.
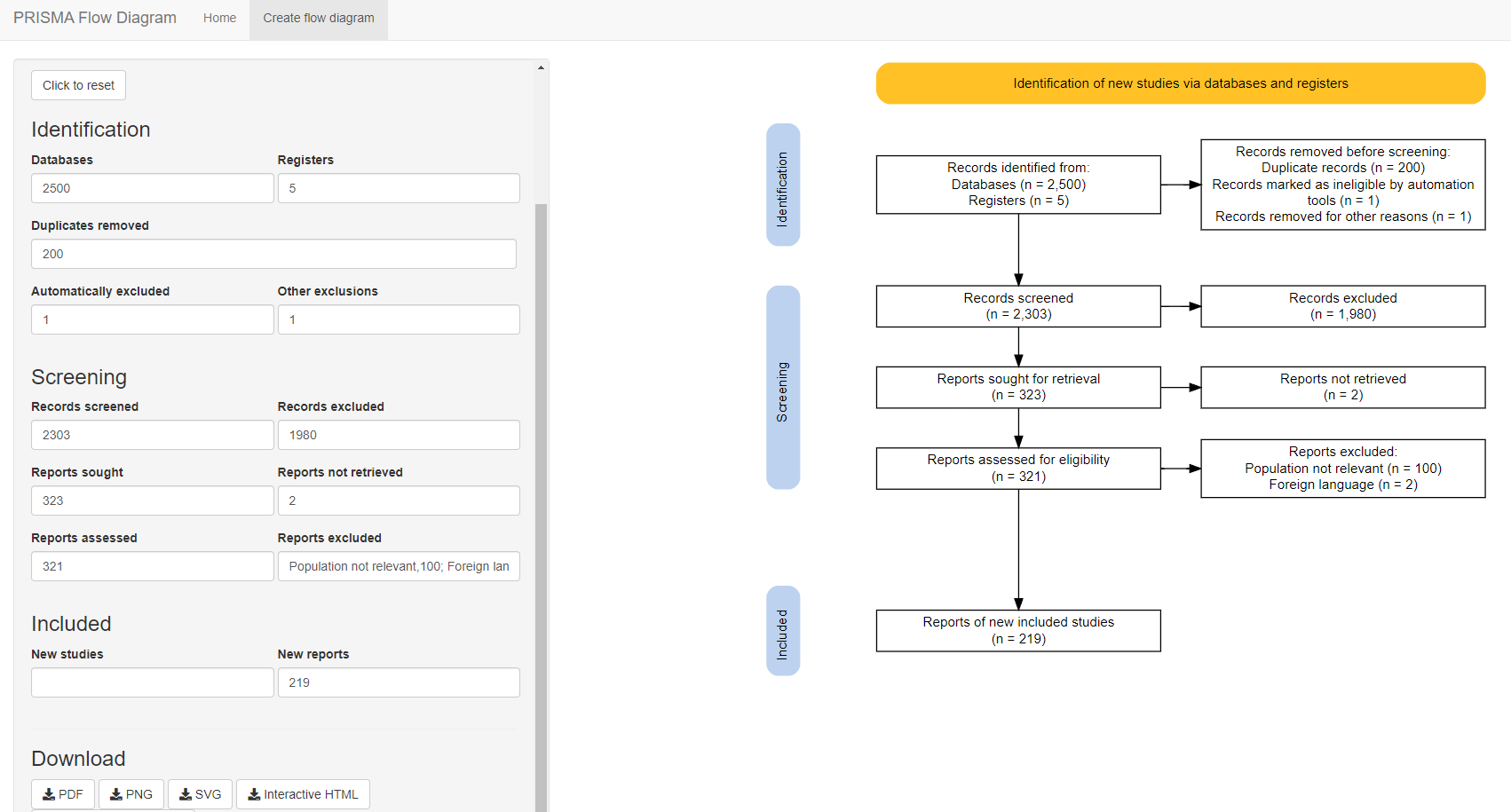
Librarian’s Take: This is a relatively simple tool to produce PRISMA 2000 flow diagrams. There is no reason not to use this if you need to produce such reports. For more details on the tool, refer to paper “PRISMA2020: An R package and Shiny app for producing PRISMA 2020-compliant flow diagrams, with interactivity for optimised digital transparency and Open Synthesis”.
Litsearchr – suggest keywords and Boolean searching rules
One query I sometimes get from users is how to choose the right keywords in a systematic way. Is there any rigorous, automatic system to figure out what would be the best keywords to use?
Litsearchr by Eliza Grames currently a PhD Candidate in Ecology and Evolutionary Biology at the University of Connecticut is a semi-automated way to do this.
Her solution Litsearchr works roughly like this:
- Search with a ‘naive’ or comprehensive boolean search across multiple databases such as Web of Science, Scopus etc and export the results in RIS.
- Import all the results in RIS into Litsearchr.
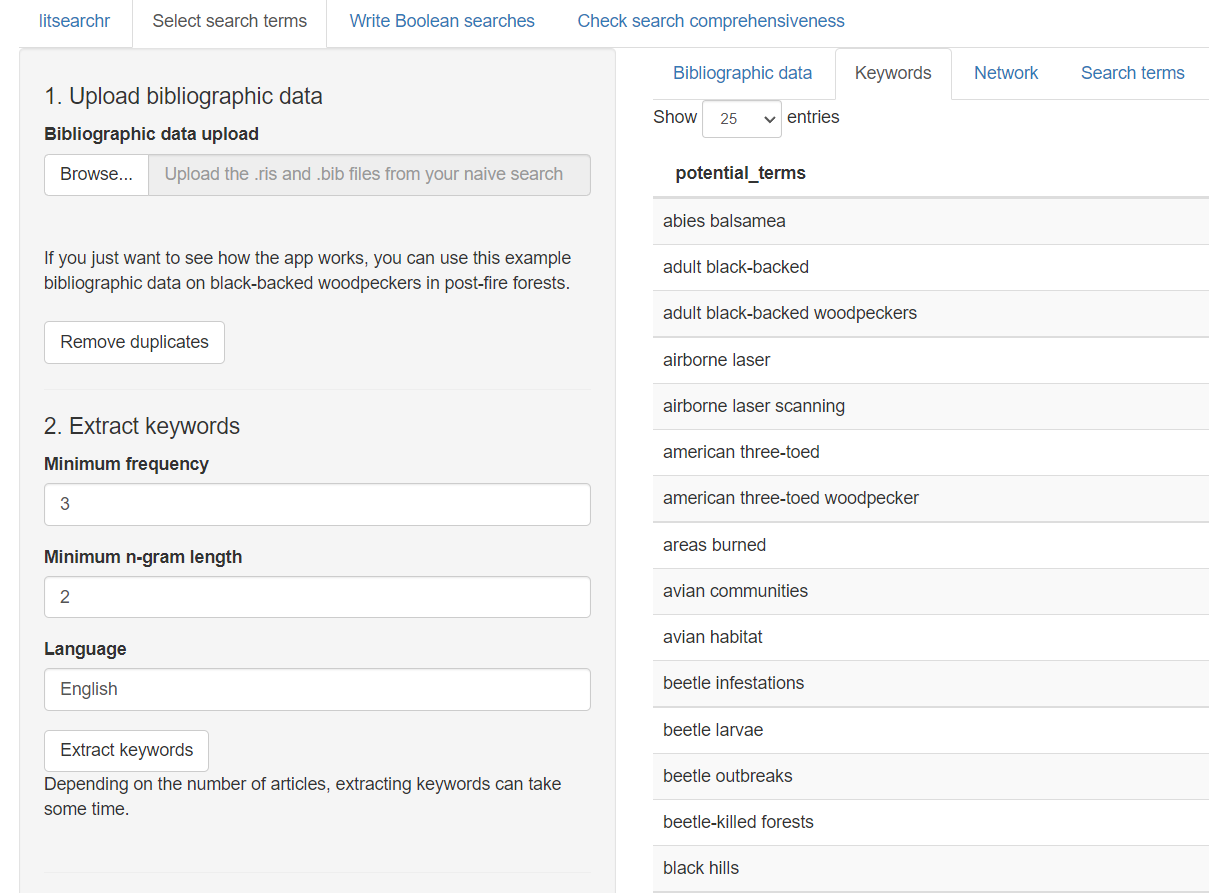
- Litsearchr will remove duplicates and use an algorithm known as Rapid Automatic Keyword Extraction algorithm to identify potential useful keyword terms. Note that this draws terms not just from author supplied keywords but also title, abstract etc.
- This usually results in thousands of potential keywords, so the system creates a co-occurrence network of the keywords based on whether the keywords co-occur in the document’s title or abstract. You can visualise the co-occurrence network, but it is usually too packed to be useful, but the keywords in the centre of the network are more important than those at the edges.
- Litresearchr allows you to set a cutoff (two possible methods) to narrow down to the most important keywords based on Node strength, this will reduce the number of potential keywords.
- Next of the remaining keywords, Litsearchr will ask you to group them into categories. For example, two potential keywords might be synonyms e.g., both are types of birds in a study on birds. Other categories that are often used are based on the PICO framework, so categories can be created for population, intervention, control, outcome etc.
- You can add additional keywords, Boolean will do some cleanup (e.g., keywords can be redundant) and Litsearchr will generate search strategies using keywords from these categories. You can even generate non-English search strategies by using Google translate API.
- Lastly you can upload gold standard papers and check how well the suggested strategies in #7 pick them up.
You can read more about the techniques in the documentation and tutorials. This tool which won the 2020 Commendation from the Society for the Improvement of Psychological Science is no doubt a very power tool to generate and test search strategies but because it is implemented as a R package, the steps to generate all these steps can be daunting if you are not familiar with R.
Thankfully recently, Eliza Grames released a shiny app of Litsearchr which provides a point and click web interface without the need to install R or enter code.
Librarian's Take: This is no doubt an interesting tool. In their paper, “An automated approach to identifying search terms for systematic reviews using keyword co-occurrence networks”, they claimed that the strategies that Litsearchr produced performed “as well as the published searches and retrieves gold-standard hits that replicated versions of the original searches do not.” They also claimed it reduced the time to conduct systematic reviews. I can’t vouch for this, but may be worth a try.