
by Aaron Tay, Lead, Data Services
By now you will probably have heard of and tried OpenAI’s ChatGPT. Some of you may have even paid to access the newest GPT4.
OpenAI’s GPT family of models have taken the world by storm. GPT or Generative Pretrainer Transformers are a type of large language model (LLM) that can generate text autoregressively via an decoder transformer architecture. But what are language models? The simplest way to explain language models is that they are a system that is trained on huge amounts of text to determine the probability of a given sequence of words occurring in a sentence. Think of it as somewhat akin to the autocomplete in your mobile keyboard.
The state of art large language models like GPT3 are huge, trained on huge amounts of text (45 billion TB from sources including Common Crawl, Wikipedia) and computing power with over 175 billion parameters and as a result have started to show astonishing capabilities in NLU (Natural Language Understanding) and NLG (Natural Language Generation).
Some researchers might be familiar with BERT (Bidirectional Encoder Representations from Transformers) language models, particularly specific ones specialized to domains like finBERT to do machine learning tasks. However, such language models tend to require further finetuning and are difficult to use for non-coders.
Generative AI language models like GPT3, ChatGPT, GPT4 etc on the other hand can accomplish a variety of tasks like code completion, text classification, Q&A tasks and more at near state of art levels with just simple prompts. For example, you can just prompt ChatGPT in plain text to classify comments into either positive sentiment or negative sentiment and it can do it relatively well. Results tend to improve if you give examples in the prompt (this is known as One or few shot prompting) but it can do okay a lot of the time with no examples(known as zero shot prompting)
Still, no doubt you would be familiar with the weakness of ChatGPT in that it tends to “hallucinate” or make up facts. This is particularly so for references, and it is prone to make up fake references when asked to create references. For example, this attempt by me to ask it to find papers that estimate the size of Google Scholar using ChatGPT(GPT3.5)
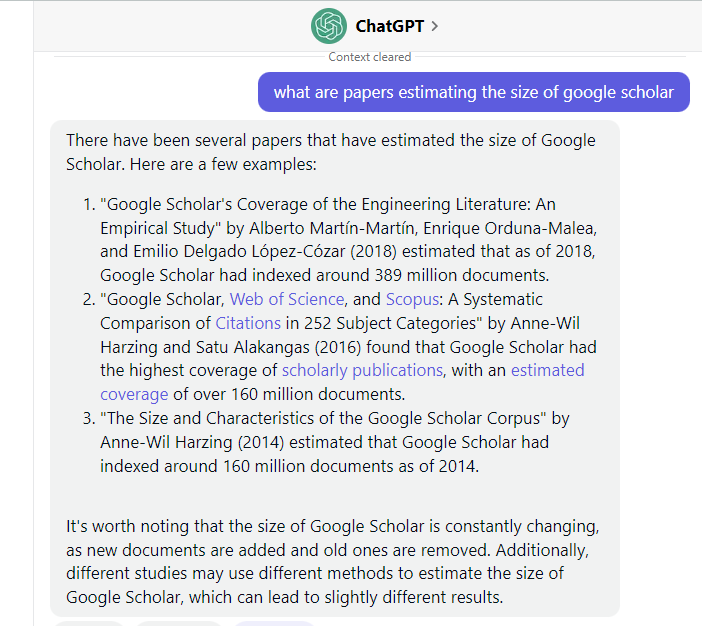
The papers look plausible but are wrong. For example, the first paper really existed but the authors are wrong and the findings of 389 million document estimates are wrong (the paper does not attempt to estimate the absolute size of Google Scholar at all). The second paper is a real paper but the authors are wrong and again the description of the papers is nonsense.
Even then the authors are not totally random – for example, Alberto Martín-Martín, Enrique Orduna-Malea, and Emilio Delgado López-Cózar have indeed published papers estimating the size of Google Scholar. Harzing (of Harzing Publish or Perish software) has not to my knowledge published papers estimating the absolute size of Google Scholar, but she has some adjunct papers that compare the size of Google Scholar vs other citation indexes.
Another issue of using ChatGPT or any LLM is that they are expensive to train and are typically working on data that is months behind. As such if you ask ChatGPT or any LLM what are the opening hours of SMU Libraries, even if it could get the right answer (GPT-4 in my tests seems much better at avoiding fake references), it would be based on the webpage it “saw” or trained on months ago! This problem will remain no matter how big the language model becomes.
So, what is the solution?
How about if we leverage the abilities of search engines and combine them with the natural language processing and natural language generation capabilities of LLM to extract the answer?
This is indeed what search engines like the new Bing+Chat, Perplexity.ai and possibly the upcoming Bard by Google do. The new Bing in particular as I write is now fully available without a waitlist.
How would such a system work? What follows gives you a rough layperson’s idea of how it might work.
- User enters a query into search and this search is interpreted and searched with a normal search engine.
- The search engine ranks the top few results as per usual based on your query.
- Instead of just displaying the results, the system will extract the sentences which are most relevant to the query.
- These most relevant sentences are then sent to the LLM with a prompt like “Answer the query in view of the sentences below"
The description above hand-waves a lot of the steps, particularly how it determines the sentences “most relevant to the query” section – this is typically done by converting both the query and text passages of top-ranked documents into embeddings (which are representations of words or sentences that capture their essence) and doing a similarity match. Refer to OpenAI Cookbook on GitHub for technical details.
In other words, instead of the LLM relying on its own training data to answer questions, it extracts the answer from the top-ranked pages and tries to use this data to answer the question.
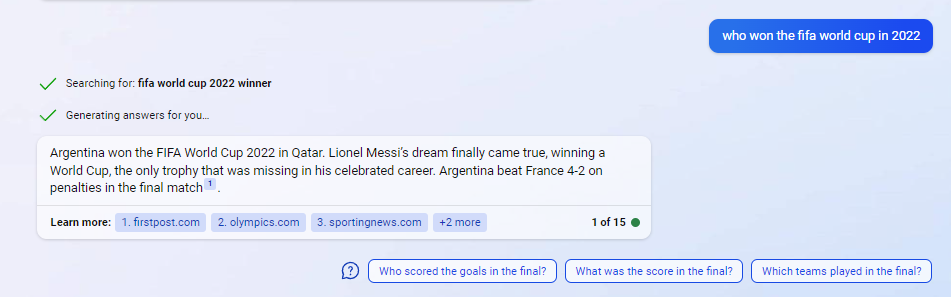
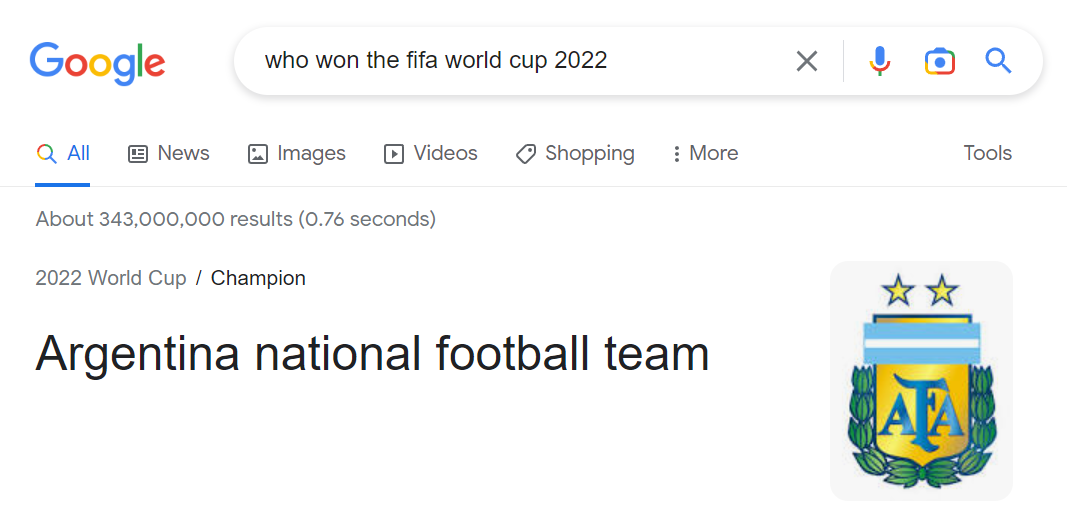
This allows it to answer questions even of current events that happened after the LLM was trained. For example, at the time of writing, if you ask ChatGPT or even GPT4 who won the FIFA world cup in 2022, it will refuse to answer saying its training data is only up to July 2021.
If you ask it with the new Bing, it will give a direct answer with a link to the sources it extracted the answer from
You may have occasionally seen similar direct answer to question in Google which is generated from Google Knowledge Graph or the featured snippet feature, but this only happens for selected questions, while for the new Bing and similar search engines, they will always give you a direct answer extracted from a webpage.
In the machine learning world, this type of task is known as Q&A (Question and Answering) task, where instead of giving you just links to documents that may be relevant to the query, it attempts to extract the right answer from the most relevant documents and passages.
The Power of doing Q&A (question and answer) over pages and papers
While Q&A or semantic search engines are not a new idea, they have not become mainstream because until recently their accuracy has not been very good. They are extremely convenient because unlike using conventional search engines you must click through the top results to look for answers, you get the answers directly extracted with a link to the page or source.
At their best they are amazingly good. Take the earlier question about papers estimating the size of Google Scholar, using Perplexity.ai, a partner with access to OpenAI’s GPT3+ models, we can see it provides very good answers using a same methodology as the new Bing (it in facts uses Bing API + GPT models)
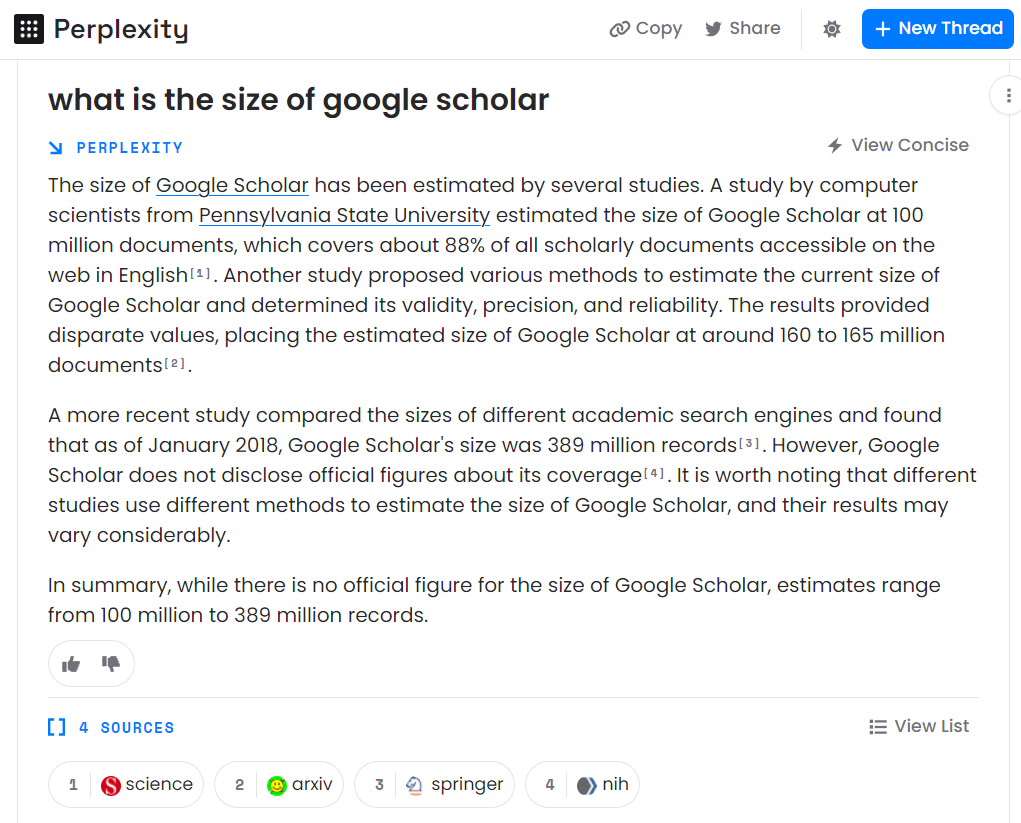
Like the new Bing, you can see the answer and the four sources it cites. On top of that, if you click on “view list”, you can expand the sources and even see the text passages it extracted to answer the question!
For example, the answer generated by Perplexity.ai cites the article "Just how big is Google Scholar? Ummm..." from the journal Science in the second sentence. If you check the "view list" source, you can even see the sentence that was used to generate the answer.
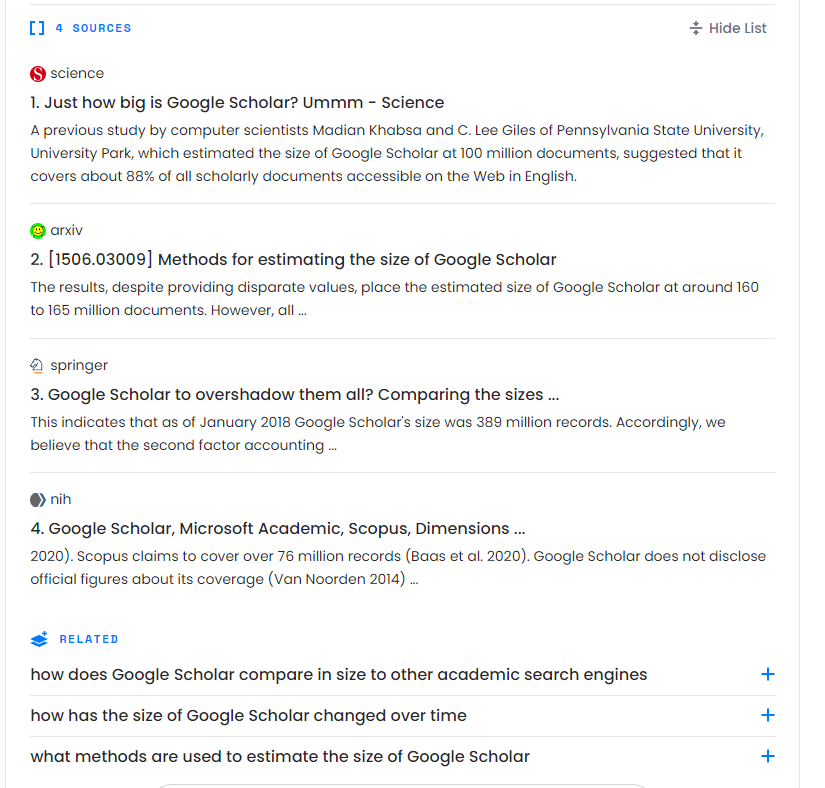
Essentially Perplexity.ai and Bing can not only “read” webpages but extract results from PDFs that are Open Access and available on the web!
In the query below in the new Bing, I enquired about the challenges single-parent families face in Singapore and it surfaced a series of results from multiple sources like Singaporesoleparent.com.sg
Not satisfied with the domain where the answers came from, I asked it to filter to only scholarly papers. (You can also ask it to filter results by specific domains)
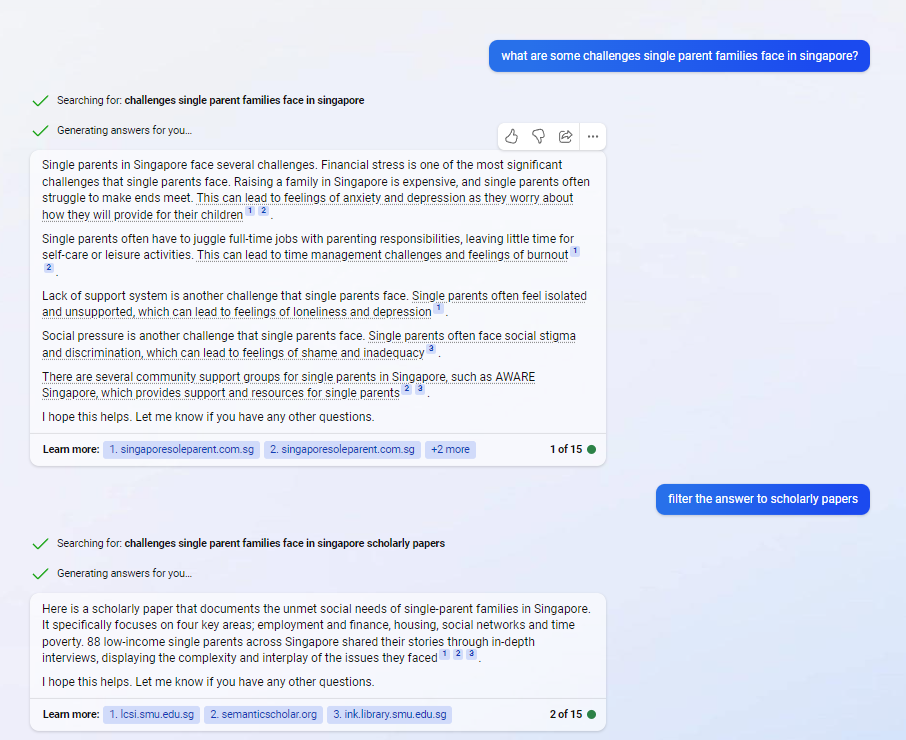
Perplexity suggested a report titled "Single-Parent Families in Singapore: Understanding the Challenges of Finances, Housing and Time Poverty". This open access paper is available on three different websites, including a copy stored at the SMU Institutional Repository- InK.
Finally, I asked Perplexity for the recommendations written in the paper/report.
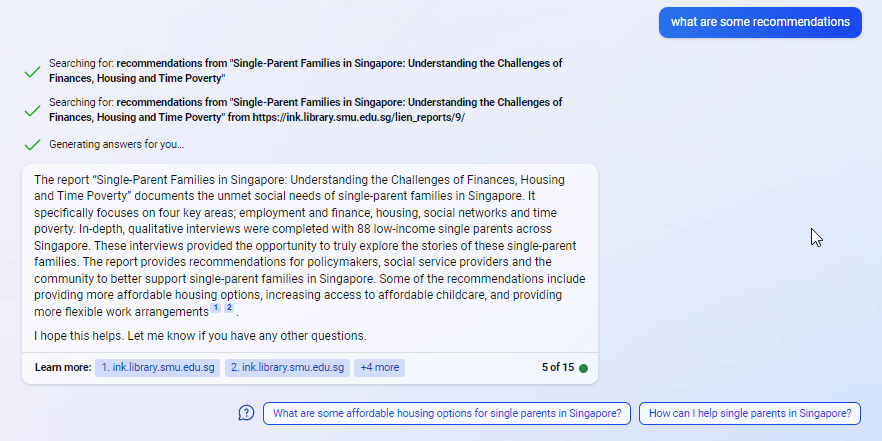
Essentially, we have now unlocked the power of open access, as these new search engines leverage the power of Large Language models to directly answer questions from Open Access papers.
Here are some other possible things you can ask using these new search engines (these barely scratch the surface of what this technology can do).
- Asking for seminal papers on a certain topic. (Bing vs Perplexity)
- Asking about datasets commonly used (Bing vs Perplexity)
- Who first coined a term
Drawbacks of using such tools and some advice
These tools like the New Bing and Perplexity.ai are an extremely new class of search engines. Earlier prototypes of these Q&A tools were either extremely domain limited (e.g., COVID only) or unreliable and nobody has much experience with them, including yours truly.
Note: While it is true that such tools unlike standalone LLMs are unlikely to make up unreal citations from scratch, they are not immune from making up (or if you prefer “misinterpreting”) what the citation is about!
For example, I see cases where it claims a paper A has a finding X, when in fact it was Paper B that did so. The LLM “got confused” by the mention of the work done by Paper B in the literature section of Paper A.
More mundanely it seems to also have problems interpreting tables of data on pages, so if it is asked about SMU Libraries opening hours or loan privileges, it finds the right pages with the answer but often confidently asserts the wrong opening hours (see actual page with information) or loan privileges (see actual page with information)!
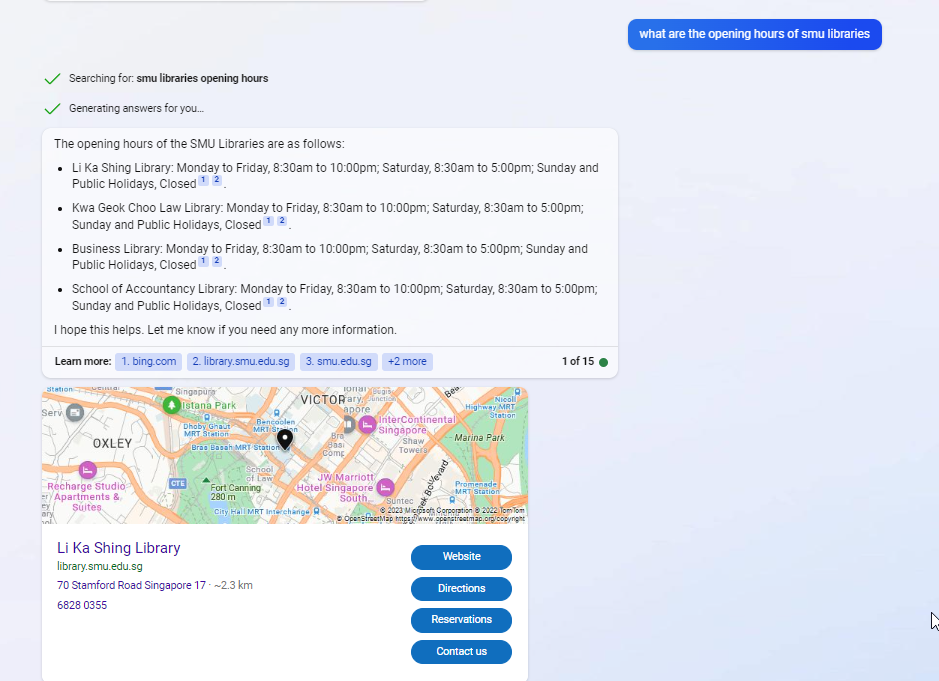
While Large Language models can be set to always give the same answer by always generating tokens (words) with the highest probability, it is often set to vary (as it is in New Bing) its answer (see the “Temperature” parameter when using OpenAI’s API), so you will get slightly different answers each time you run it even with the same query and the page doesn’t change. I have found when it gives the wrong answer (extracts or misinterprets information from the page), rerunning it many times tends to give the wrong answer but once in a blue moon it gets it correct.
Given the above, if one chooses to rely on such tools, I highly recommend you use it with caution. Do not assume the answers given are correct without checking the source or cross checking with other sources.
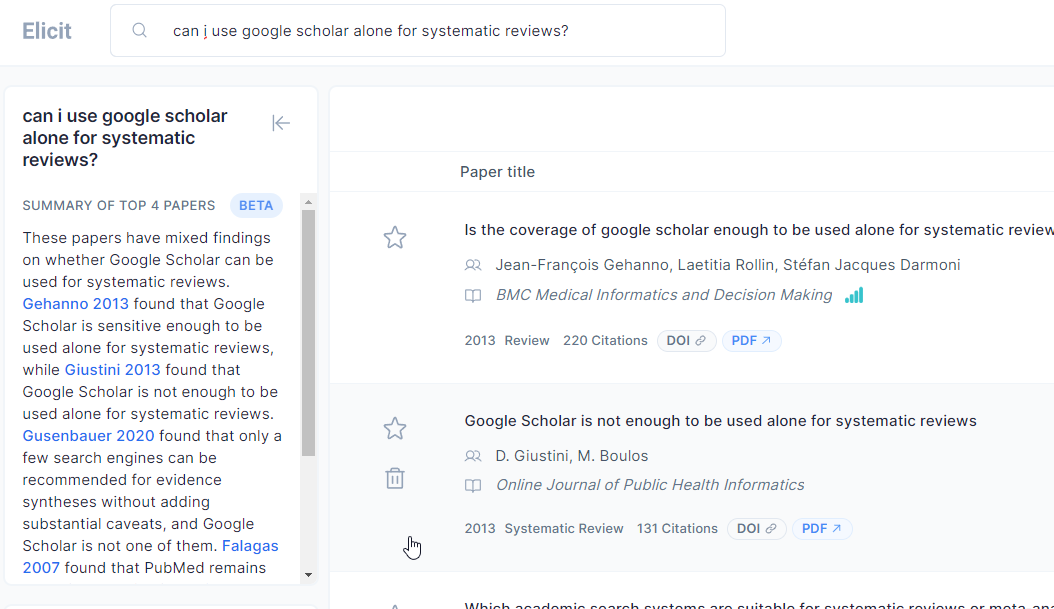
While I am not aware of a study that has formally studied the accuracy of these new systems, Elicit.org, an academic search engine akin to the new Bing (except searching over only academic papers from Semantic Scholar) has a roughly 70% accuracy rate in extracting characteristics of papers.
I expect accuracy rates to improve but answers should never be trusted without verifying from the source.
The answers given also heavily rely on what are the top ranked documents, you may want to prompt the system to ask for any more information by prompting it with “more results”, “more information” etc.
If you are looking for academic only information, you might want to use equalvants to Bing or Perplexity search except that they cover only academic papers (akin to Google Scholar). These currently include, Elicit.org, Scite.ai’s beta ask a question, Consensus.app and Scispace. Lastly, see the newly announced CORE-GPT application which combines “Open Access research and AI for credible, trustworthy question answering".
Of these, Elicit.org is the most mature, and I will review it in a future ResearchRadar piece.
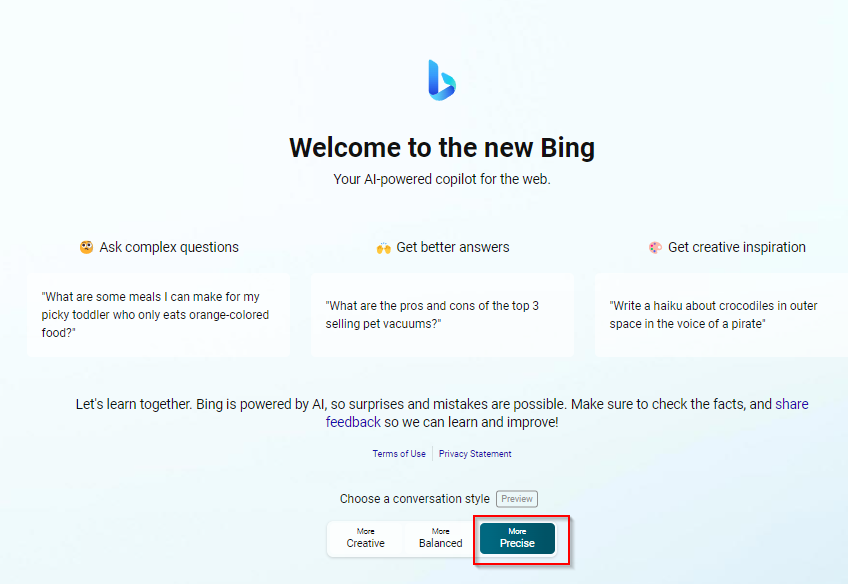
Finally, if accuracy is paramount, Bing currently offered a “More Precise” mode which you can use. It tends to be even less likely than the default “More balanced” mode to be wrong but at the cost of refusing to answer or giving very sparse replies.
Conclusion - Is adding search definitely better?
In this piece, I briefly compared using LLMs alone with the new search engines like the new Bing and Perplexity.ai that combine traditional search engines with LLM to extract answers directly. While for information retrieval tasks, it seems to me the latter is preferred, there are other use cases where you might just want to use a LLM such as ChatGPT or GPT4 alone without search.
For example, if you use Bing and asked it to role-play a historical figure and his views on a new topic, Bing might search and find no relevant results and refuse to play along. While doing it with just a large language model alone it tends to try to do the requested task. You can try to stop Bing from searching by prompting it to “Do NOT search” or “There are no relevant results” but it does not always comply.
The line for when to encourage it to search or not search is not entirely clear to me, for example, people have been testing ChatGPT heavily to see how good it is at generating boolean searches for systematic review. Would using the new Bing which can add information from webpages help? On one hand, it might help that it can extract and reuse hedges/filters from pages such as this, on the other hand, the content from the search results might distract and worsen the generated answer.
All in all, this new class of search engines is something unprecedented, while it typically acts like a Q&A search engine by searching for webpages and extracting results, it can also answer without searching like a typical conversational bot.
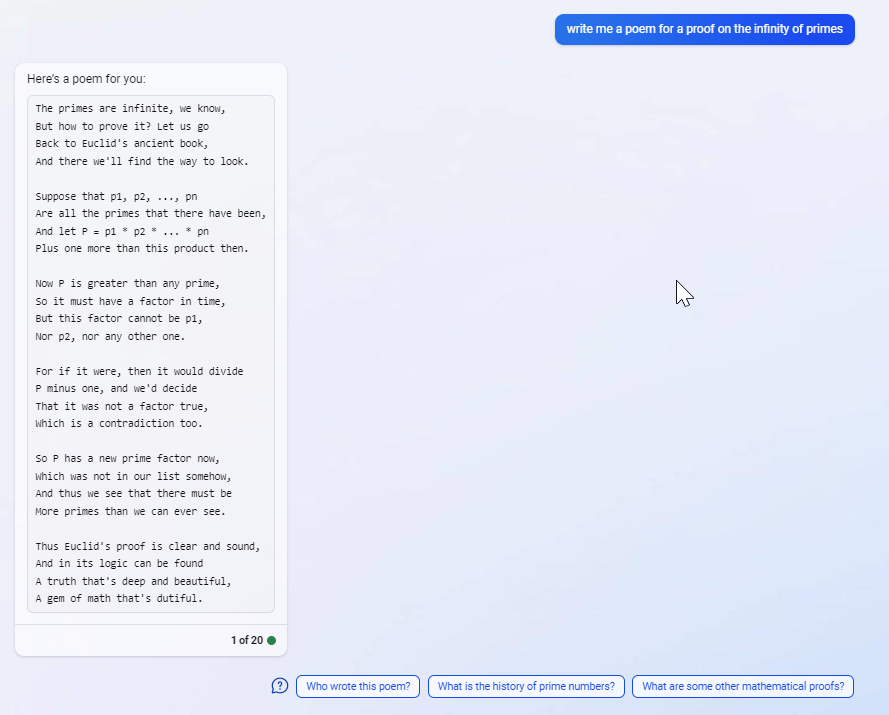
See example below where Bing acts like ChatGPT, GPT4 and creates a poem from scratch for a proof of the infinity of primes without searching.
More research is needed on this new class of tools.