
By Aaron Tay, Lead, Data Services, Dong Danping, Senior Librarian, Research Services, Bella Ratmelia, Librarian, Data Services & Heng Su Li, Research Associate, College of Integrative Studies
On 18 January 2024, SMU Libraries in collaboration with SMU Researchers Club, hosted a webinar by SciSpace, an AI-powered discovery tool that can generate direct answers to questions with citations, answer specific questions posed to individual articles and even extract information to create a research matrix of studies.
The webinar was presented by Saikiran Chandha, Co-Founder & CEO of Scispace who presented and demoed SciSpace for 30 minutes. This is the first of several webinars on AI-Powered Research Tools that SMU Libraries will host in 2024.
This presentation was attended by 109 people online and around 40 people in person. There were over 40 questions sent through the Q&A polling system during the 30-minute Q&A session.

The questions were wide-ranging, spanning from feature requests, technical questions on the LLMs used, clarifications on the data sources and techniques used and a lot more.
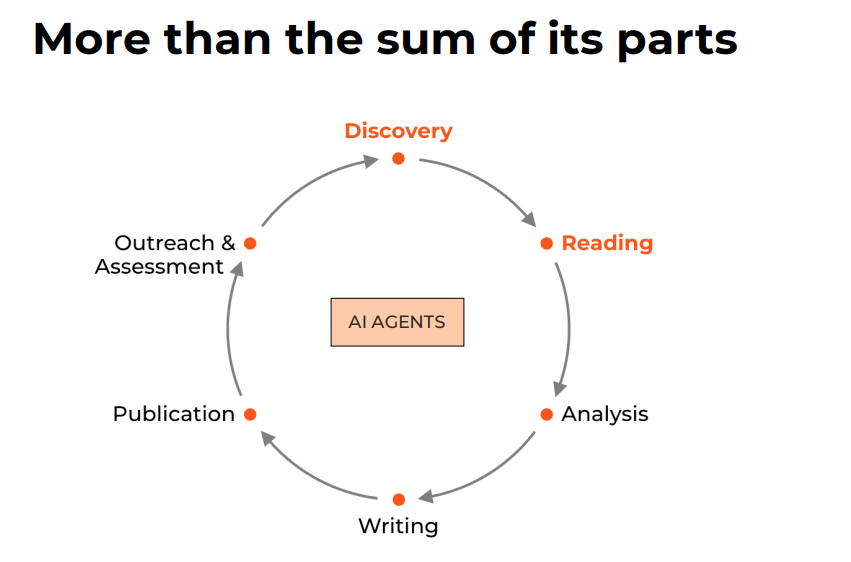
It was an extremely informative session with Saikirian setting out the overall vision of his company which is to improve and automate research tasks throughout the whole research workflow with AI agents, with the current model covering the “Discovery” and “Reading” phases with more tools in the future to cover the “data analysis”, “writing” and “publication” phase. Features to support writing tasks is expected to be released in Feb 2022.
Insights from top 5 papers
During the webinar, Saikiran showcased the capabilities of SciSpace. For example, Scispace acts like an “AI agent” that is able to generate a summary from the top 5 ranked papers.
During the Q&A, he also mentioned that there might be a feature increasing this to possibly as high as 25 top papers in the future.
He also explained how unlike conventional search engines that used keyword searching, Scispace represents documents and queries as embeddings and finds semantically similar papers.
He did warn of a particular drawback, because Scispace uses Semantic Search, it may not always match a specific keyword (e.g. specific gene, method) that you may want, as such, you can filter down specifically to keywords in the abstract in the interface.
He also clarified during the Q&A that this default sort is purely by relevancy and does not include citation counts in the rankings (you can of course do a further filter by citations next).
Technical Note: SciSpace converts all documents to embeddings pre search. The query is then converted to embeddings during the search and the embeddings with the closest similarity are found. SciSpace first does a initial retrieval of the top 10000 papers, followed by a a reranking using more precise but more computationally expensive model that is finetuned for academic search to yield a final top 100.
Other interesting post filters includes Publication year, journal and conferences and a recently launched filter - “Top-tier papers” filters to articles from journals ranked as Q1 in Scimargo Journal Ranking (SJR).
In terms of the sources of Scispace, they use OpenAlex, Semantic Scholar and their own crawlers that crawl websites, repositories like Arxiv, Bioarxiv of around 200 million documents represented as embeddings.
In a question about whether Scispace can pick up works with no DOI, Saikiran mentioned that it while “most likely” things with DOI would be picked up, this is not so certain for non-DOI works. While it might pick up some no-DOI papers from its sources (author note, Semantic Scholar does include non-DOI content) and from its crawlers, there is no guarantee it can pick non-DOI works up. I would add this probably means it is not likely to pick up law cases and might also not cover law journals that are not usually often in usual academic “non-law” databases.
One way around it would be to upload the full-text of the PDFs yourself into “mylibrary” for extraction.
If you are interested in any article, clicking on it and selecting “show more like this”, will lead to Scispace to search through the citations, the references, and all the other articles that are semantically relevant to the article that you selected.
Scispace extracts information to help productivity and AI bots helps with comprehension of papers
Besides generating a summary paragraph from the top 5 papers, Scispace is also capable of extracting information from papers to generate a table of studies, with columns such as “Insights”, “Conclusions”, “Limitations” etc and a lot more predefined field. You can also create custom columns with other fields that are not predefined. This allows you to quickly skim through papers.
During the Q&A, Saikiran mentioned that data extracted from the global search only extracted from abstract and not full-text even from Open Access papers, unlike uploading PDFs which uses both. But post webinar, he clarified that the global search “does retrieve answers from full-text" but “uses a different technique not using the embeddings”.
Hallucinations and trustworthiness of AI generated answers
Throughout the talk he warned about not trusting SciSpace completely, and that despite all the carefully crafted prompts, finetuning of embedding models, hallucinations are still possible in SciSpace answers.
When asked about the types of queries or extractions SciSpace was more likely to have high accuracy and to whether SciSpace has a benchmark on accuracy, he admitted that this was an extremely difficult question that the whole industry was studying.
The recording of the webinar is available on Zoom (please login to Zoom with your SMU account via SSO login).
If you are interested in getting a trial account for SciSpace Premium, please email us.
Network party event after for the SMU Researcher Club
The discussion did not stop here for the live audience. SMU research staff have been invited to an informal networking lunch, a first of its kind, organised by the SMU Researcher Club and co-hosted by SMU Libraries.
This is an initiative that is co-organised by SMU Libraries and Heng Su Li (CIS) to connect researchers in SMU with each other to exchange ideas and share experiences.
Over 40 research staff from various schools and centres joined in the fun, getting to know each other through an ice-breaker game, sharing candid feedback about their experiences with AI-powered tools, and exchanging ideas on subsequent activities for the club that would improve their work.
The interactions amongst the research staff and librarians resulted in meaningful insight that will help undergird the services and resources the library and club will roll out next time.


Lastly, if you have any comments or suggestions about other AI-powered tools that you are eager to share, drop us an email at library@smu.edu.sg.
