
https://consensus.app/By Aaron Tay, Head, Data Services
The SMU community is not a stranger to the latest AI academic search tools. We have subscriptions to top tier tools like Undermind.ai, Scopus AI, Scite Assistant and more.
To these tools, we now add Consensus on an extended trial until Aug 2026.
To get free access to Consensus Pro account, just register with your SMU email, verify via your email and you are done!
Want to know what's unique about Consensus and how it differs from other AI academic search tools that we have access to like Undermind.ai? Read on.
Basics of Consensus
At the basic level Consensus works similarly to many of the tools already mentioned. You enter your query in natural language, it queries its index returns the top few results and it generates an answer with citations.
Consensus provides a Consensus Search Best Practices that provides examples of natural language input it can handle well. This tutorial provides even more detailed help.
Similar to Undermind.ai, Elicit.com, it uses generally open sources, in particular OpenAlex and Semantic Scholar, which means it typically will have abstracts of papers but only open access full text (approximately 200M including preprints). Many such tools also have partnerships with selected publishers to enhance access to full-text but this is still likely to be a small part of the index.
One of the unique features of Consensus – and the feature that gives this product the name is that for certain types of questions and where there are enough relevant papers found, it can generate a "Consensus meter", which tries to estimate the "Consensus" from the set of papers on the same topic.
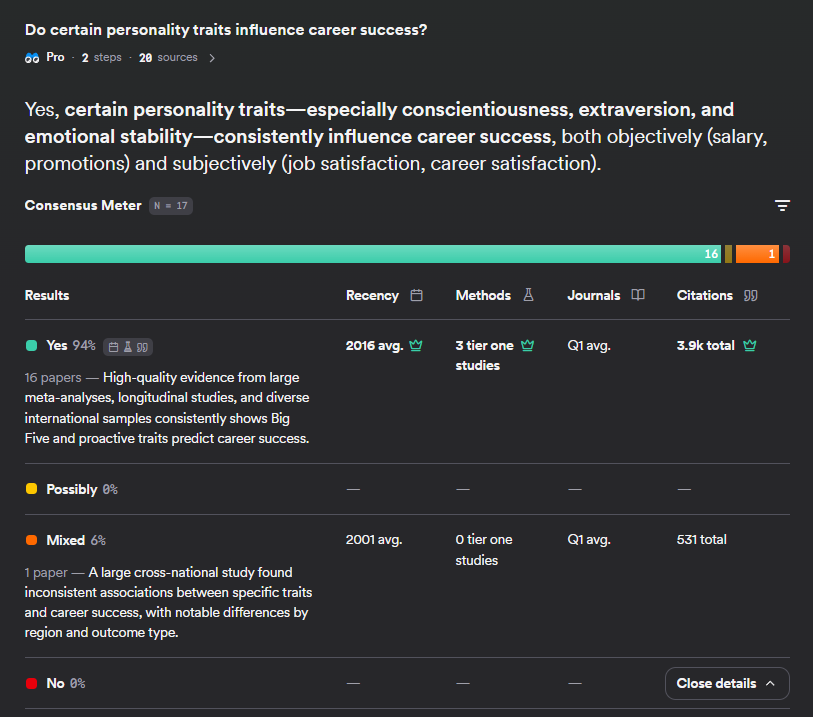
In the above example, you can see for the query "Do certain personality traits influence career success?", you get a nice visualisation showing 16 papers or 94% of the relevant papers found say "Yes", with 6% (1) saying the results are "mixed"
But can we trust the papers saying "yes"?
In the details, you can see for the average paper that says "yes", what their average recency, Journal Quartile Tier and citation count is. Moreover, In the example above, you can see of those 16 papers that say "yes", 3 are "Tier one studies", which is defined as RCT (Randomized Controlled Trials).
In short, these are proxy signals for quality that help you get a sense of the average quality of papers that are found.
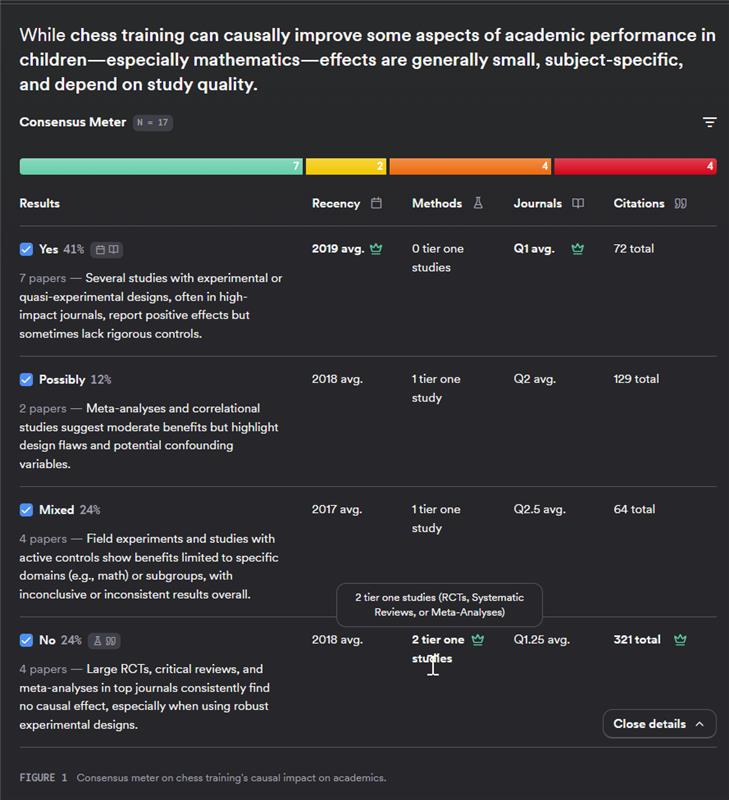
For example, in this deep search on “Does chess training causally improve academic performance in children?” the Consensus Meter shows that 41% (7 studies) say “yes,” 12% (2 studies) say “possibly,” 24% (4 studies) say “mixed,” and 24% (4 studies) say “no.” At first glance the results look close. However, none of the seven “yes” studies are tier-one (randomised controlled trials, systematic reviews, or meta-analyses), while the tier-one studies are among the more negative results. This suggests the higher-quality evidence tends to be negative, and the overall weight of evidence points to no causal effect.
You can of course ignore both the generated answers and consensus meter and focus on the search results which has 3 layouts - "Default", "Compact", "Table", with the "Table" setting being most interesting.
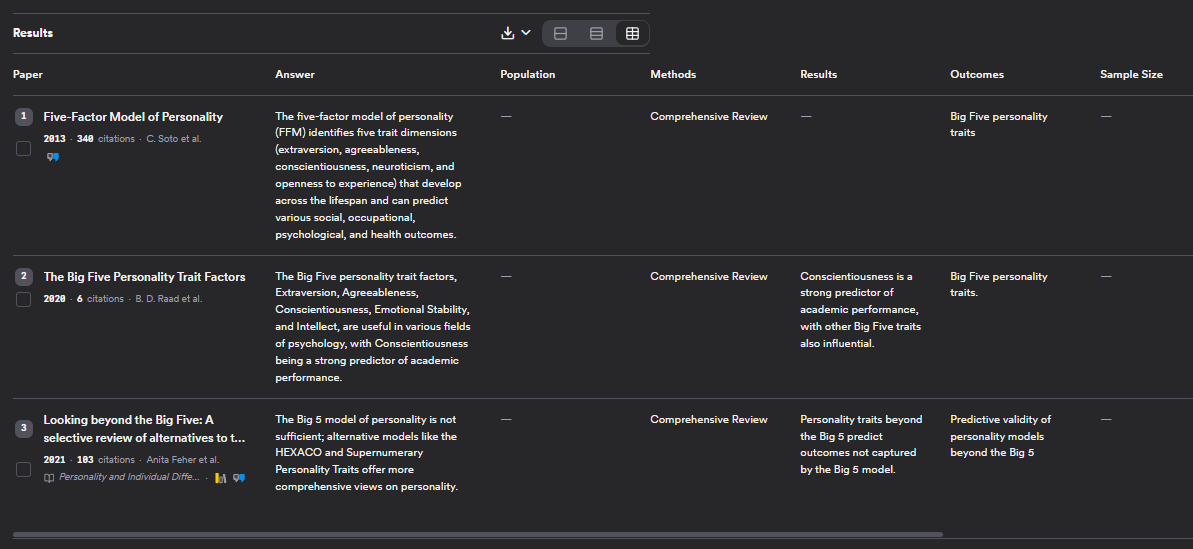
Consensus not only lists the papers but uses LLMs to extract information about "population", "methods", "results", "outcomes" and "Sample size". This is the same extraction you get when you click on individual papers to generate "Study snapshots".
Unlike some other tools like Elicit or SciSpace you cannot create additional custom columns of information.
Many of the papers in the results are also tagged with information on whether they are RCT (randomized controlled trials), highly cited, or even "rigorous" or "very rigorous journals" to "help users better understand the quality of their search results". How is "rigorous journals" defined? Seems like they are using SciScore, with "rigorous journals" being in the top 50 percentile of journals and "very rigorous journals"in the top 10 percentile.
Another useful feature is Consensus has Libkey support. As such, you can go to settings and go to preferences and set your institution as Singapore Management University. This enables Consensus to "know" how to link to the full text of papers available via SMU subscriptions.
Search Settings of Consensus.ai
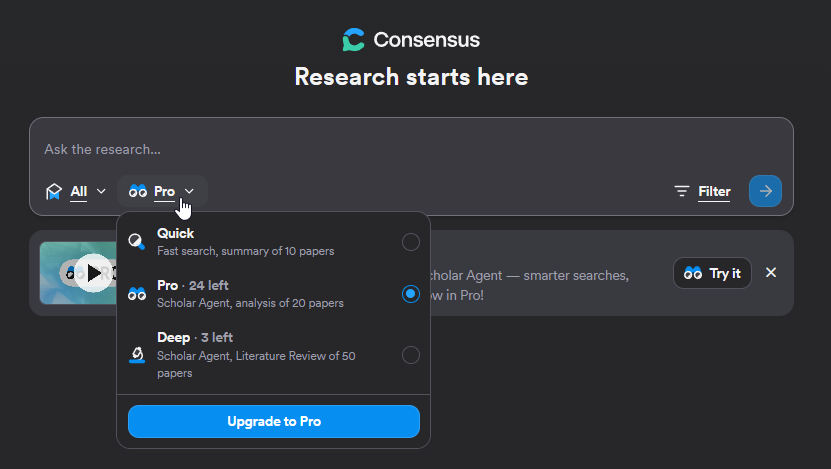
Like many academic AI search tools, it provides a setting that determines roughly how much "effort" it will do to search and in the case of Consensus how many papers it will try to summarise.
"Quick" summarises max 10 papers, "Pro" summarises max 20 papers and "Deep" summarises max 50 papers.
The search itself uses a hybrid keyword search and semantic search (embeddings match) which is again very common today to take advanatage of the strengths of both types of retrevial algos.
Again following best industry practice, their search involves a multiple stage ranking procedure. First, the top 1,500 results from the hybird search are further reranked taking into account not "just by how well they match your query, but also by how strong the research is".
This takes into account, citation count, recency of publication and journal reputation and impact. While this explicit ranking by quality and not just textual relevancy is not unheard of, my understanding is that this is still somewhat rare - espically for many of the newer offering in this area. This is follows by one last reranking step that optimises for the top 20 results.
As I write this review, Consensus has announced in collaboration with OpenAI, "Scholar Agent" which is used in "Pro" and "Deep" mode. Under the hood this means Consensus is now using GPT5 and the response API and the post even includes a flow diagram of how the planning agent, search agent, reading agent work together.
Another somewhat unique feature about Consensus is that they provide a wide variety of pre-filters you can use to control the search. This is less common for current AI-powered search systems.
Besides the newly introduced "medical mode" that restrict the search to 8 million papers and guidelines drawn from: ~50,000 clinical guidelines, and The top 1,000 medical journals worldwide., there are also a variety of other prefilters.
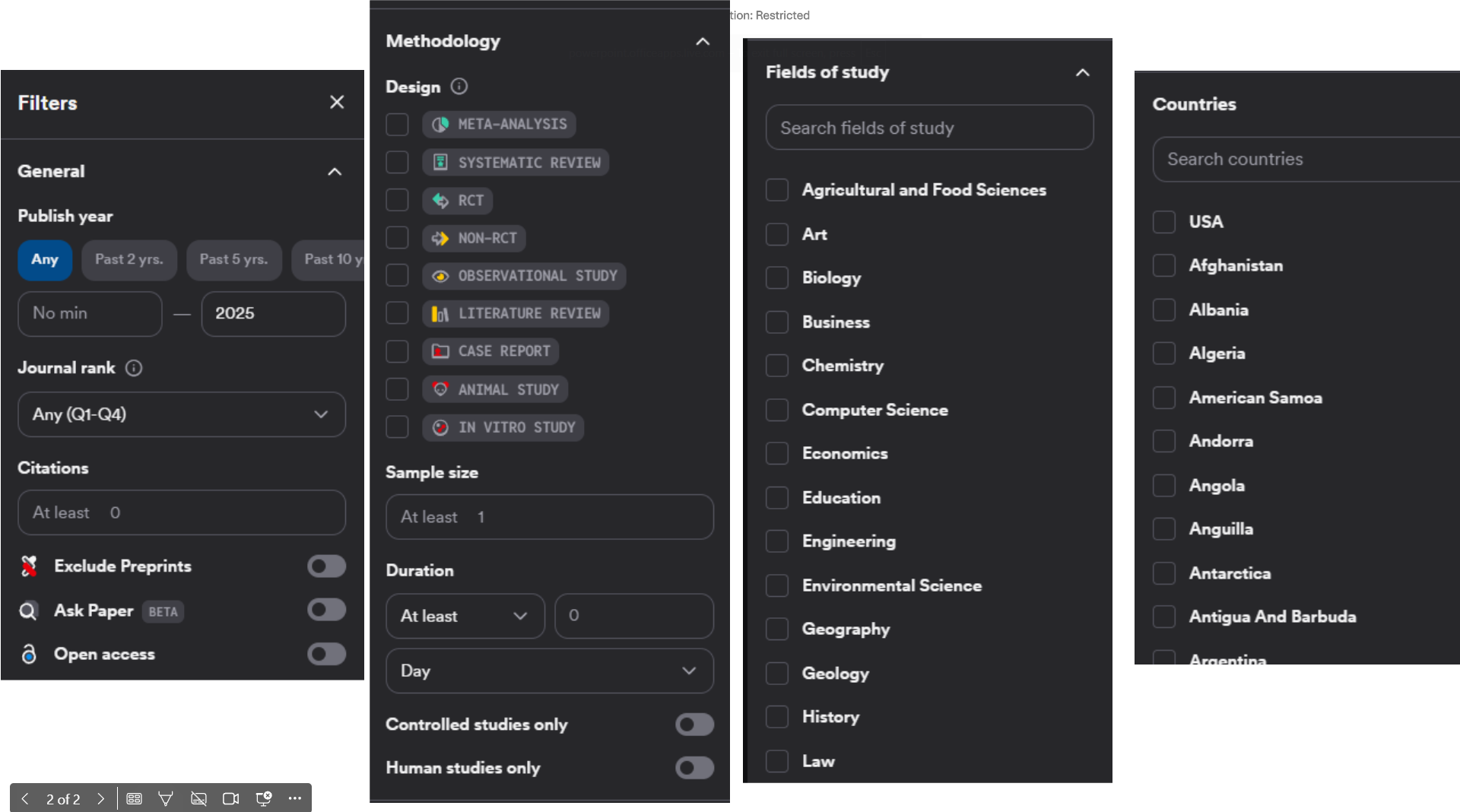
You can filter by some of the usual suspects such as publish year, Scimago Journal Rank, citation count, exclude preprints etc.
Somewhat less commonly you can be filter by methodology. One big way is by design, so you can include only for example. Meta-analysis, RCT, Systematic review etc. Another way is by Sample size. Note that these classficiations are by AI/LLMs and may not be accurate.
Lastly, you can filter by field of study (23) and countries (236).
Consensus Deep Search – search process
I have written about the trend towards Deep Research with general tools like OpenAI/Gemini Deep Research as well as academic search implementations like Undermind.ai, Scopus Deep Research, ASTA summarize paper, and more.
Consensus version of this is called Deep Search.
It is interesting perhaps to compare Consensus Deep Search with Undermind.ai (which we also have a subscription)
Both Undermind and Consensus Deep Search take <10 minutes with Consensus being a bit faster.
One major difference is while Undermind will ask clarifying questions, Consensus Deep Search just searches straight away.
That said, some librarians dislike the fact that Undermind's search process is 100% non transparent.
In comparison with Consensus Deep Search, you get a PRISMA like flow diagram of the literature search and flow diagram.
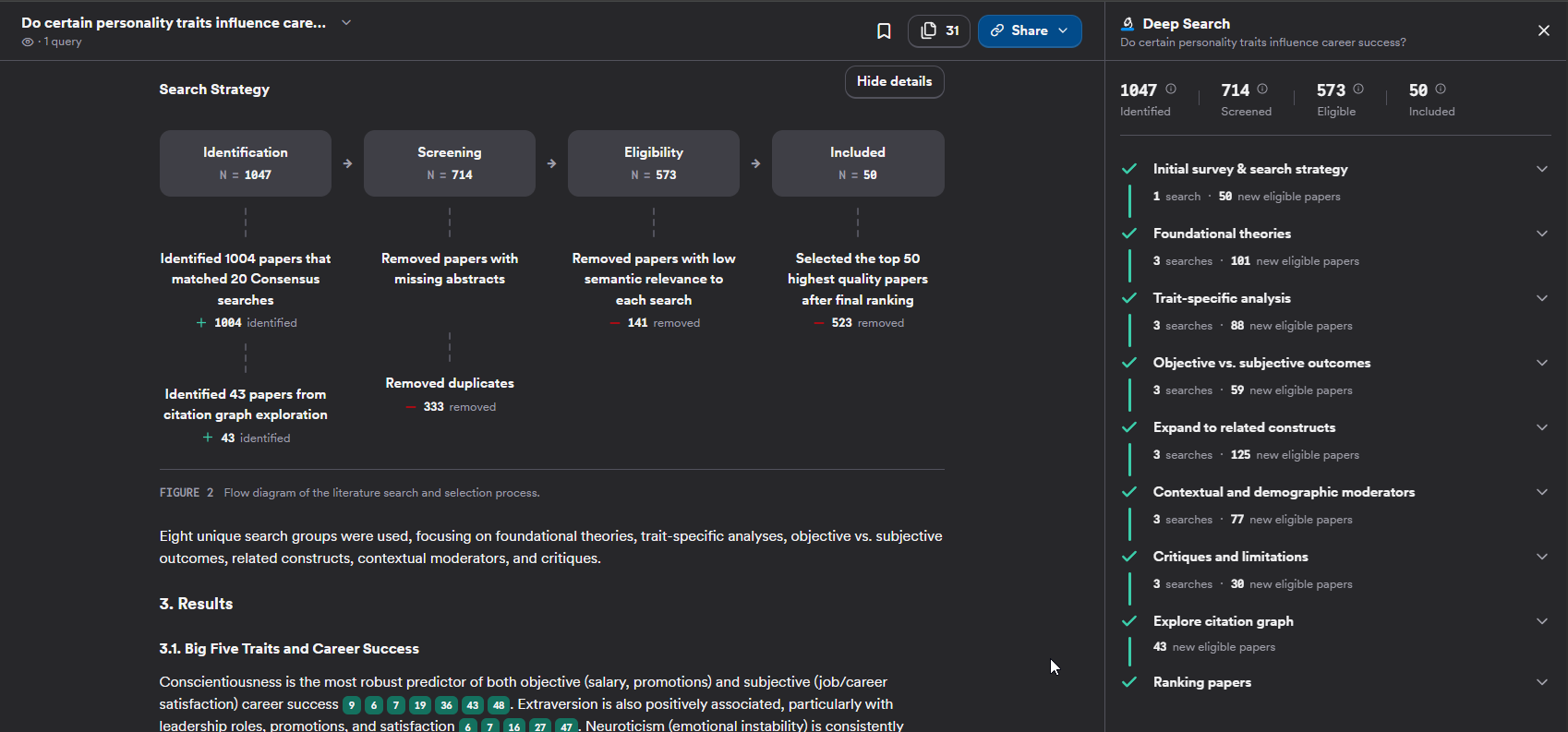
In the example, above you can see the Deep Search run 20 searches, with 1004 hits. 43 more papers was identified using citation searching with a total of 1047 hits. After removing papers without abstracts and dupes (-333), you get 714.
They remove another 141 papers with "low semantic relevance" leaving 573 that are eligible to be selected and of these the top 50 are selected (probably after another rerank).
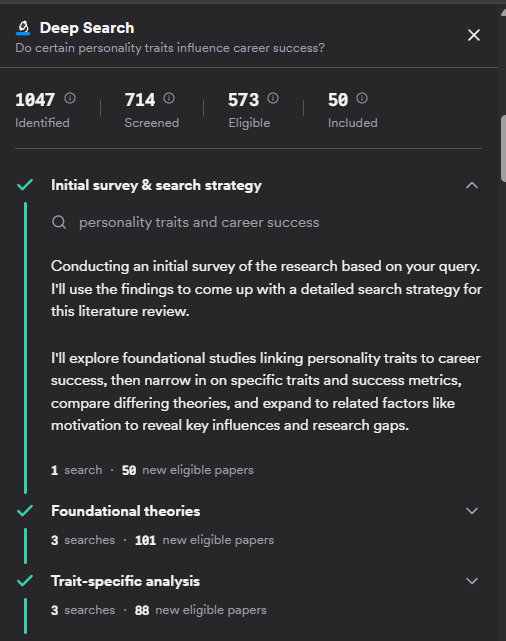
The sidebar gives even more details, and you can click on the drop down of each section to show what queries were done.

We even know the criteria used to do citation searching
Consensus Deep Search – output
Like many modern Deep Research tools, Consensus Deep Search provides a long form report with many interesting visualisations. See report here.
One particularly unique feature is that not only does the text include citations like most tools, the tools are coloured into green, yellow, orange, red which correspond to the classification in the Consensus meter for "yes", "possibly", "mixed", "no" etc. The small document icon with a tick let's you know if Consensus used the full-text of the paper or just had access to the title abstract.

Besides the already mentioned Consensus Meter, consensus deep search also offers a "results timeline", "Top Contributors" table, "Claims and Evidence Table", "Research Gaps Matrix" and "Open Research Questions"
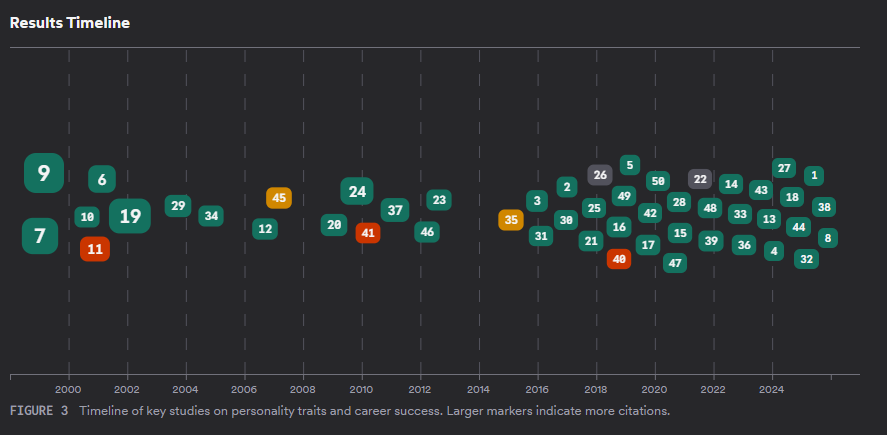
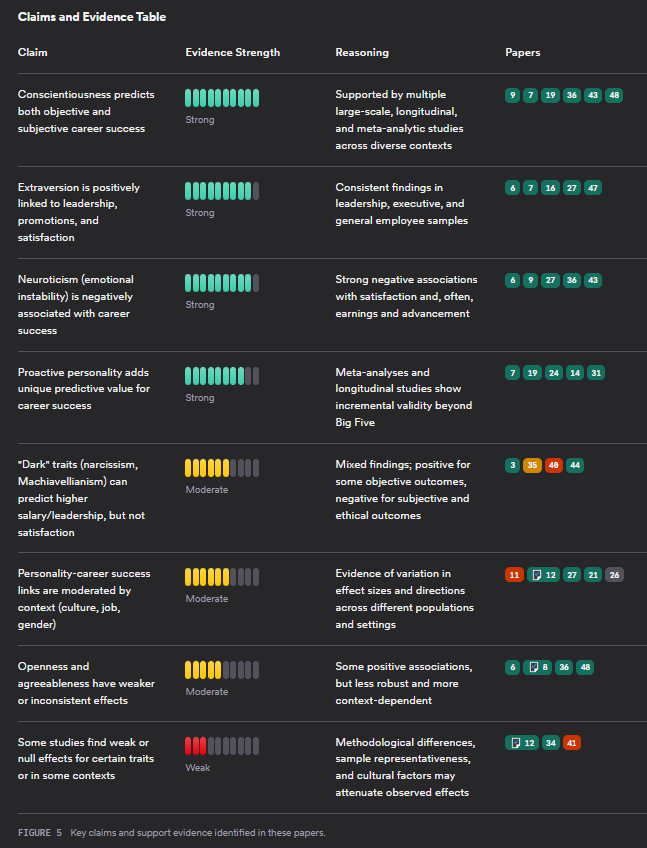
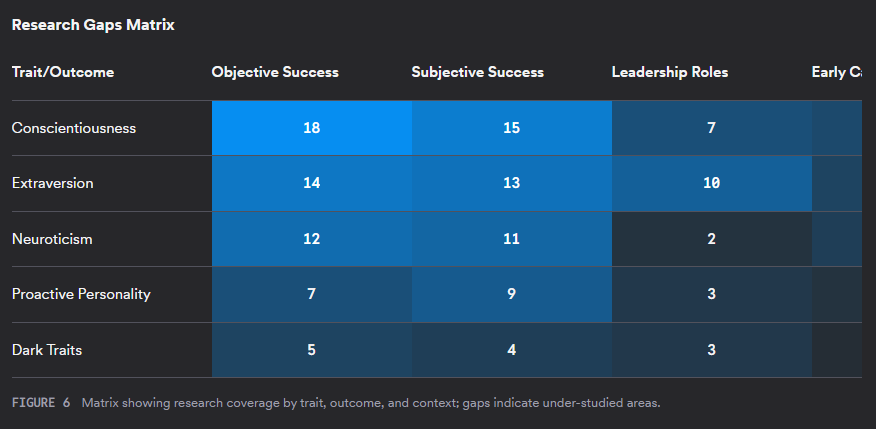

Some of these visualisations are similar to what you can also get via Undermind and some are different and it's a matter of preference which one you like.
Conclusion and comparison to Undermind.ai
Consensus is a very powerful AI powered academic search tool similar to Undermind.ai searching roughly the same sources.
It differs from Undermind.ai in terms of having more prefilters and having a more transparent search. Its Deep Search has visualisations that are quite standard in this class of tools, but there are also more unique ones like the Claims & Evidence table and the Consensus Meter.
You can see from the various details extracted and the filters available that Consensus has a clear STEM and medical slant. While many will like the fact that Consensus explictly tries to rank based on strength of the paper and not just relevance, this can be tricky to do particularly when some of the signals for strength of paper are biased e.g journal based and I am particularly skeptical about the use of SciScore metrics as a proxy for research quality.
Even if SciScore does capture "research quality" at the individual paper level (e.g. reproducibility of method), I wonder if it might be STEM specific or biased and may not work well for other fields like Business or Social Sciences.
Still the sources Consensus use are as broad as what is used by Undermind etc so coverage shouldn't be an issue. But more testing is needed to ensure the retrieval algo and LLM is not fine-tuned to doing well for medical only.
Like any tool that uses LLMs to extract and summarise you will have to be careful about hallucinations. Consensus claims that it has solved the problem of fake sources and will never cite a paper or article that doesn't exist as well as Wrong facts, and it will never generates a confident answer from internal memory that’s simply incorrect with no source. This is no doubt done using non-LLMs methods to do a check if a) every citation corresponds to something in their index and a mechanism to enforce the rule that b) every generated statement has a citation.
However like pretty much all tools in it's class (e.g Undermind.ai), it is still vulnerable to what Consensus calls misread sources - where it summarises a real paper wrongly. They have some safeguards to reduce this but that is not 100% reliable.
While Consensus claims that they make it easy for you to check the sources to verify yourself, I have found it not to be always true particularly when the citation is to something in the full-text. Clicking on "details button" doesn't seem to jump me to the portion of the text that was used by Consensus, so verification is hard.
At the end of the day, both Undermind and Consensus are excellent and for me personally, which one to use would come down to which one was better at retrieving all the relevant papers in your topic, and this can only be determined with a lot of comparison testing in the area you care about.
