
Update: 13 Feb 2025 - since I wrote this in 2021, Large Language Models(LLM) like GPT, Gemini, Claude Sonnet etc have become powerful enough that they can be used to help with many of these tasks. For example, you can copy and paste references from papers, put them into a state of art LLM and prompt it to convert into RIS files. You can even try uploading full pdfs and asking the LLMs to extract. They can also be used for extraction of text from older "Image PDFs" where you can't copy and paste text. etc. They aren't perfect and may occasionally hallucinate though.
By Aaron Tay, Lead, Data Services
Doing systematic reviews, thematic reviews and review papers in general is getting popular beyond the usual disciplines of Medicine, Psychology and Education.
For example, in the business disciplines we see the following paper aims to “develop a rigorous review protocol ...that researchers can rely upon to guide and justify decisions in systematic literature reviews” published in the International Journal of Consumer Studies. Another similar paper is - The art of crafting a systematic literature review in entrepreneurship research and there is even guidance on doing meta-analysis in marketing domains.
Even if you are not interested in doing systematic reviews and meta-analysis, you might still be doing thematic reviews, conceptual review papers and just review papers in general in the field of business. Similarly, there has been quite a bit of guidance on writing such reviews in areas from International Business, Management Studies, Marketing and more (see shared Zotero Library).
However, while such articles give much guidance on the principles and higher aspects of doing searching, screening, and selection, you may run into more practical issues. We can help with that!
For example, how do you check and add in missing DOIs for a large set of papers? Or how do you extract and convert references from plain text to RIS/BibTex format (a standard format for lists of bibliography items used by reference managers)? Finally, what is the fastest way to download the PDFs of a given set of papers with DOIs (Digital Object Identifier) in as few clicks as possible? Obviously, all of these can be checked manually, but when doing a review or systematic review, you can be dealing with hundreds to thousands of such records. How can you do this in bulk and be efficient as possible to save time?
Converting plain-text/references created by hand into RIS/BibTeX
When doing reviews, you are typically dealing with large numbers of references and papers. While you can manage them in Word or Excel spreadsheets, it is advisable to manage them in RIS or BibTeX formats.
As you may be aware, when dealing with bibliographic data these are the formats of choice and they are well supported by most reference managers like EndNote, Zotero or Mendeley. As you will see later, converting your collection of papers into such formats is critical because it makes it easy to use other tools do bulk extraction, cleaning, and manipulation of the data.
For example, you will often need to do deduplication of references and having them in RIS/BibTeX means you can import them all into a reference manager like Zotero or Mendeley and make use of their dedupe functions. While databases and academic search engines (e.g. Google Scholar) support exporting RIS/BibTeX formats, what if you only have the references in plain text?
Say you have a Word document with the references and bibliography.
There are two possible scenerios.
Firstly, the references in the Word document were created using the Zotero/Mendeley plugin or Word's build-in reference function. In this case, the references are already in structured format (even though they may be hidden). You can extract and convert them near perfectly into RIS using the Reference Extractor tool (If they were created using the Word Reference function, you can export them using a variety of reference managers – here's instruction for Zotero).
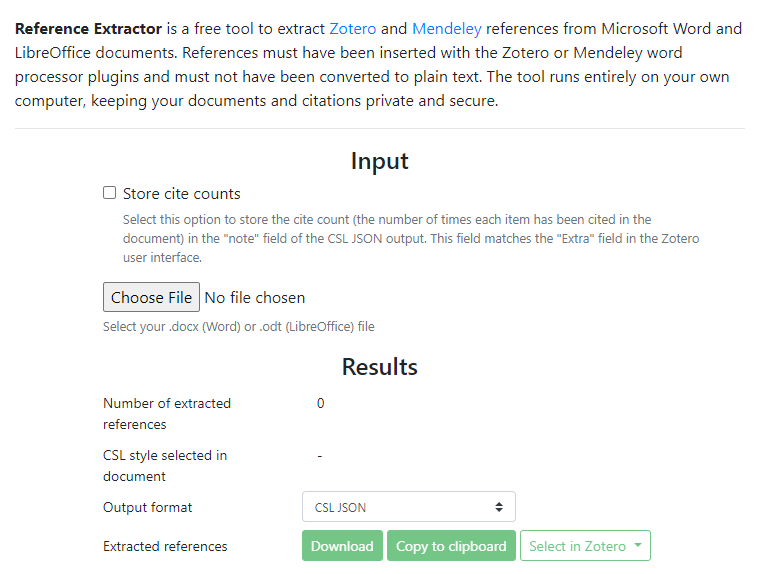
However, if the references in Word were manually created by hand, things get tricky.
You can cut and paste the full references into citation parsers like AnyStyle.io or Scholarcy Reference Parser which will try to recognise the various reference elements (e.g. author, source title, publication year) . In this situation, while this works decently for more commonly used styles, for other unusual styles or unusual citations, the parser may fail to properly parse or interpret your manually created references and the conversion might not be completely correct.
More advanced users who find the methods above lacking can also run open source software like GROBID tool directly to extract the references into RIS/BibTex and even train the model to better work for specific citation styles.
For more details, refer to the FAQ (Frequently Asked Questions) - How do I export my references and bibliography in MS Word to RIS/BibTeX?
Checking metadata of your references for omitted and missing DOIs
As you search and add papers to your collection, depending on the source you are using, the quality of the metadata you get on the selected papers may vary. Or you may inherit references that have poor quality metadata from Excel worksheets, Word documents or even RIS/BibTeX files.
Among the missing metadata fields, DOI (the digital object identifier) is one of the most important fields for journal articles since they clearly identify the paper.
How do we automatically check a lot of papers for missing DOIs and add them in as fast and efficient as possible? How do you then automatically check for missing DOI, and automatically replace with the correct DOI if available (Note: Not all journal articles have DOI, e.g. Some Law journals and some articles published prior to 2000s may lack them).
We have a FAQ on how to do this in an efficient way and it suggests two ways:
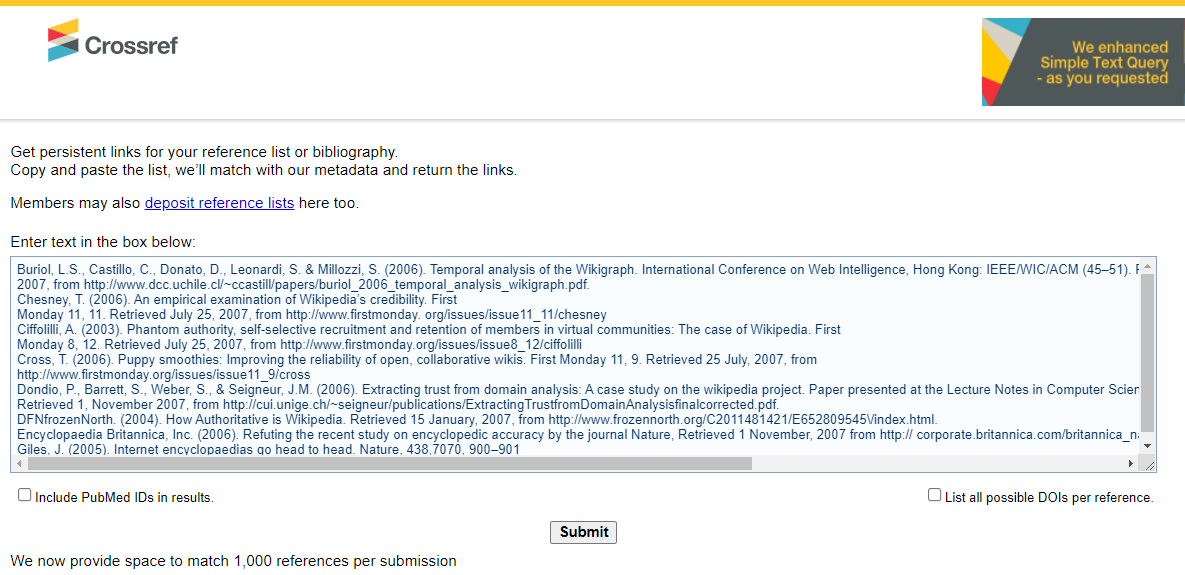
Firstly, you can use the web form for the Crossref's Simple Text Query which works if you have the references in text format and all you need to do is to cut and paste the bibliography into the web form and it will check for DOI matches.
Technical Note: Crossref is a major DOI registration agency for journal articles
Secondly, if you have the references in RIS or BibTeX format already, an easier and more efficient way to add missing DOI is to use the reference manager Zotero.
Install the DOI Manager add-on, then import the references into Zotero. With the plugin installed, it will automatically check for missing DOI for every new reference imported, query Crossref metadata search and insert the appropriate DOI if available.
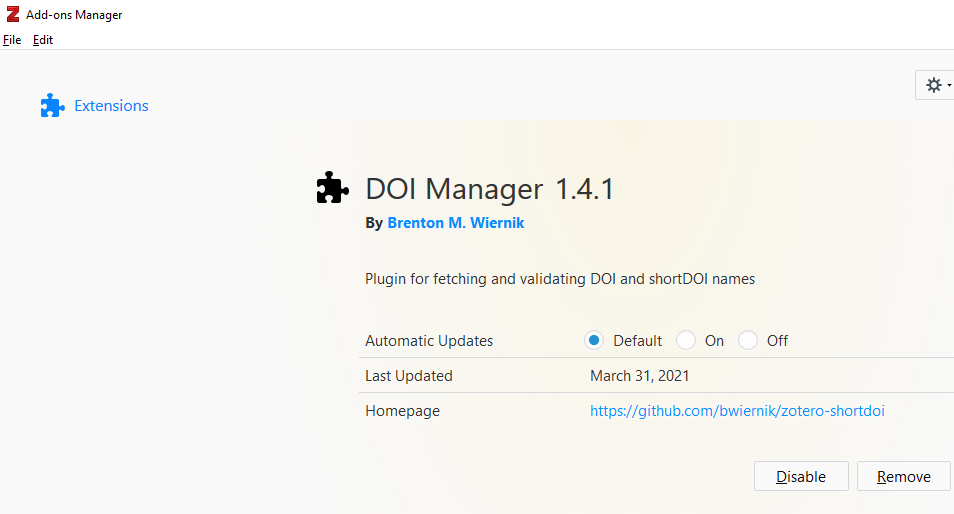
Please note that the query of Crossref procedure to find the right DOIs is typically correct, however it is possible for wrong matches to occur or also for it to miss DOIs that exist.
If the procedure fails to find DOIs, they will be tagged “No DOI found” in Zotero. I would recommend manually confirming that these articles have no DOIs.
Lastly, if the volume of references you want to check for DOIs are high, say above 1,000, you may want to directly use the Crossref metadata API to query, please contact the Libraries for support if needed.
Going quickly from DOI to PDF
The final step after reviewing and screening papers by title and abstract is to download the PDFs for reading or even text mining.
Related: See earlier Research Radar piece on - ASReview – Screen papers for literature review using machine learning.
At this stage you typically will have a DOI for each journal article. How do you go as quickly as possible from the DOI to the PDF (via legal sources available to the SMU community of course)?
While you can manually search for the item by title or by resolving the DOI, this may not always lead you to the PDF link. You often need to jump through a few more steps, e.g. from the article landing/abstract page and a click or two more to the actual PDF. In some cases, you may even land up on the wrong platform and are denied access even though you may have access via another platform (e.g. Aggregator Ebscohost or Proquest).
Is there a better way?
What I recommend is to using Libkey.io. (Note: This is what the extension Libkey Nomad does behind the scenes).

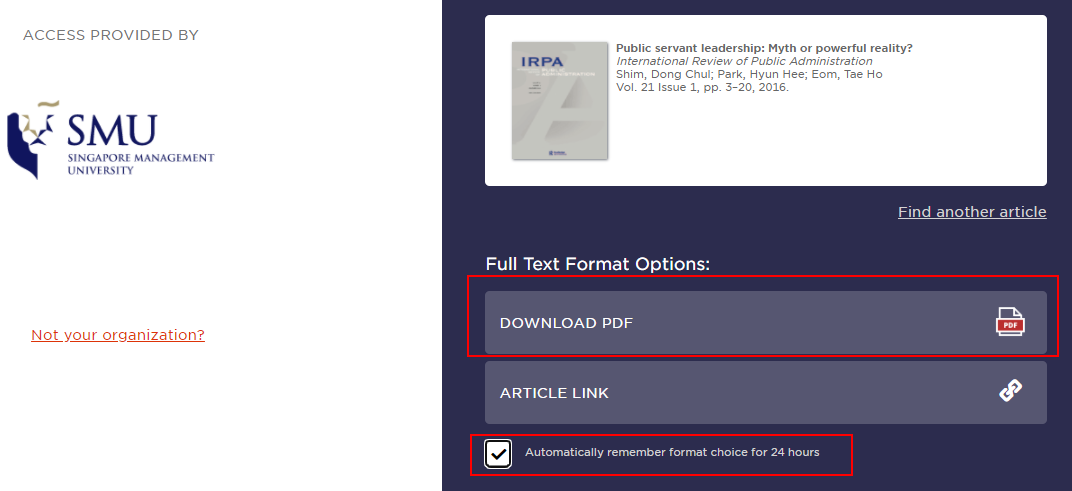
- Go to https://libkey.io/libraries/646
- Enter the DOI and click enter
- If the article is available via our subscriptions or if there is a free Open copy, you can click on the “Download PDF” option to go direct to the PDF
- To further save time, you should also check the option “Automatically remember format choice for 24 hours” before clicking on the “Download PDF” option, so that future DOIs will go straight to the PDF link without going through this intermediate link
- If we do not have access to the paper via our subscriptions, you can click on “Library Access Options” which might offer you the option of getting the library to get the paper for you (Document Delivery)
This method has several advantages over other alternative methods.
Firstly, this method works for almost all SMU journal subscriptions, not just publishers like Elsevier, Wiley, SpringerNature but also aggregators like Ebsco (important for various APA Psychology journals and business journals) and Proquest and usually gets you to the PDF.
Secondly, if you try this on an article that is not in our subscription or not Open Access, you will be directed to the Libraries’ Inter-library Loan or Document Delivery Service function. You can to request for the item in a few clicks without the need to re-enter the item details.
If this is still slow for you, many publishers (e.g. Elsevier, Wiley, Sage) allow access to text mining APIs (see this custom SMU guide) that can get you the full-text in bulk. Please consult the Libraries if you wish to explore this option.
Have other questions on managing references in bulk? Contact us for an appointment!