
By Aaron Tay, Lead, Data Services
In this article, I review Ought’s Elicit.org, one of the new academic search engines that leverages the power of state of art Large Language Models(LLM) -including OpenAI’s GPT models, BERT type models to improve search experience in different ways.
While the use of such technologies in search engines is still in its infancy, Elicit.org was probably one of the first academic search engines to start experimenting with this (early partner of OpenAI’s GPT3 API) as early as 2021 and for me, the combined feature set and user experience feels more polished and well thought out compared to other similar tools.
That said, the use of LLMs to extract answers will never be totally reliable so caution is needed when using such tools, but Elicit.org also makes it easy by highlighting the text that is used to generate the answers making verification easier.
Introduction
In last month’s Research Radar - The new Bing chat and Elicit.org - the power of search engines with Large Language Models (LLM) like GPT, we discussed the differences between using a Large Language Model like GPT3. ChatGPT , GPT4 etc as compared to using a tool like the new Bing+Chat or Perplexity.ai which combines traditional search with large language models.
We discussed how using ChatGPT and GPT4 alone to generate answers has two drawbacks. Firstly, it tends to “hallucinate” or make up answers with no way for you to verify answers. More importantly, even if it does not, its answers are limited to the data it was trained with and this tends to be at least months out of date, and it can never be trusted with answering questions that change frequently such as opening hours.
As I write this, OpenAI has announced the launch of ChatGPT plugins, which extend the ability of their language models to use different tools such as a code interpreter and even a Wolfram Alpha plug to cover weaknesses in math. Of course, for the purposes of this piece it is the launch of a web browser plugin to browse the web that is most relevant.
The last is essentially of course like the new Bing+Chat.
Is there a Google Scholar version of this new search technology?
All these are exciting developments, but tools like Bing+Chat and Perplexity.ai are still general web search engines and search over all webpages and not just academic papers. While you can prompt these systems to show or filter only to peer-reviewed or scholarly papers, this is not always respected. Is there a way to do a search across scholarly papers only the same way Google Scholar does?
How much academic content is used to train the base model in GPT-3, ChatGPT, GPT4? It’s hard to tell, particularly in the case of GPT-4 where there are no details on what is being trained, but based on some tests, I suspect ChatGPT at least is likely to have only Open Access content included. Either way, searching across academic content can help cover this gap.
In fact, there are a couple of such tools that have emerged, some that even predate the new Bing.
- Elicit.org
- Scispace
- Consensus.ai
- Zeta-alpha
- Scite.ai Assistant (new – 5th April 2023, SMU has subscription)
In this research radar piece, I will start by covering Elicit.org
Elicit.org by Ought was one of the first partner apps listed by OpenAI back in Dec 2021, that was using GPT3 API models for improving literature review search and is probably one of the earliest adopters of OpenAI GPT3+ models. Having tried the tool since Dec 2021 and given feedback in the past several times on desired use cases, I have seen the tool evolve greatly into its current form with multiple functions.
Besides its straightforward use as an academic search engine, it has the following additional functions:
- Elicit as a Q&A (Question and answer) system
- For the generation of a table of comparison of papers (Literature review research matrix of papers)
- As a quick way to query details of individual papers
Elicit.org as a Q&A (Question and answer) system
Elicit generates answers over search results like how Bing+Chat, Perplexity do it but only over academic content (mostly articles). But where does it get the metadata and even full-text of academic papers? It gets it from the open data corpus made available by Semantic Scholar.
At the time of writing, Elicit is a completely free product but this might change in the future.
If you use Elicit today to search and type in a question with a question mark, you will see an answer generated from extracts of the top 4 results.
For a more technical explanation of how it works see the prompt Elicit.org uses to generate the answer from top ranked text contexts retrieved.
In the example below, I use the sample query “Can you use Google Scholar alone to do systematic review?”
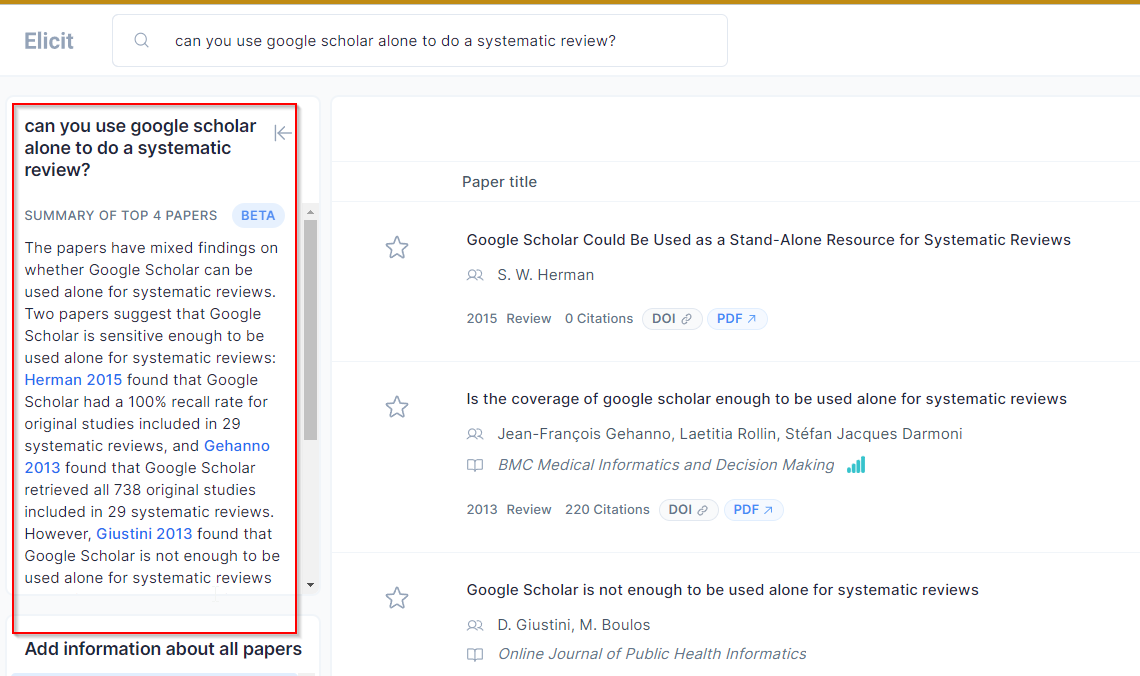
How good are the results? In my sample query above on whether you can use Google Scholar alone for systematic review, Elicit does identify the key papers and even summarize each one correctly. However, the way it strings together the findings are probably not ideal. Critically it does not explain why Giustini (2013) concludes that Google Scholar is not enough to be used alone for systematic reviews as opposed to Gehanno (2013).
The reason if you are interested is that Gehanno (2013) uses a methodology that assumes you already knew the title of the article that is relevant and are checking backwards by doing a known title search. But, if you tried to use Google Scholar alone from the start to identify relevant papers by searching keywords, the limitations of Google Scholar as a search engine e.g., limited Boolean, limited character length, 1k maximum results etc, means it is not precise enough to find most of the relevant papers alone (Giustini 2013).
In fact, the generated answer for this example is at least not erroneous, but I have seen a few cases where it makes up what a paper is saying. I am unaware of any studies that try to measure this, but I ballpark it is roughly 70% “accurate”.
In general, Elicit only uses text context from the top 4 ranked documents (which is a bit low compared to say Perplexity.ai which may draw on the top 10). I find the quality of the answer can be very dependent on the top 4 papers that surfaced.
As such you may want to experiment with keywords and/or use filters like publication date, study type (e.g., Randomized Control Trial, Review, Systematic Review, Meta-analysis etc) to surface answers from more recent or higher quality papers before looking at the generated answer.
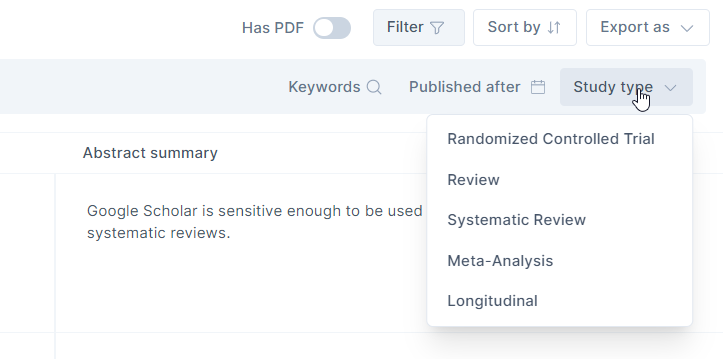
Clicking on the Star Icon next to relevant papers and clicking “show more like starred” will find papers that cite or were cited by those papers. This mimics in a small way the capabilities of tools like ResearchRabbit, Connectedpapers which we have reviewed in past articles.
All in all, the answers generated by Elicit should be taken with caution, I highly recommend you read through the papers cited as well to see if the citation/interpretation of the paper is correct and not assume that the top 4 sources cited in Elicit answers are necessarily the best sources available.
For generation of a table of comparison of papers (Literature review research matrix of papers)
Would it surprise you to know that the function to generate a direct answer from the top ranked results was a fairly recent addition?
This feature was added recently on September 2022, prior to that it was using large language models but in a very different way.
What Elicit did was to generate a list of results like Google or Google scholar but the main difference was it would generate a table of results, with each row representing a paper and each column a property of the paper.
In the example below, you can see not just a list of papers but a table of results with columns.
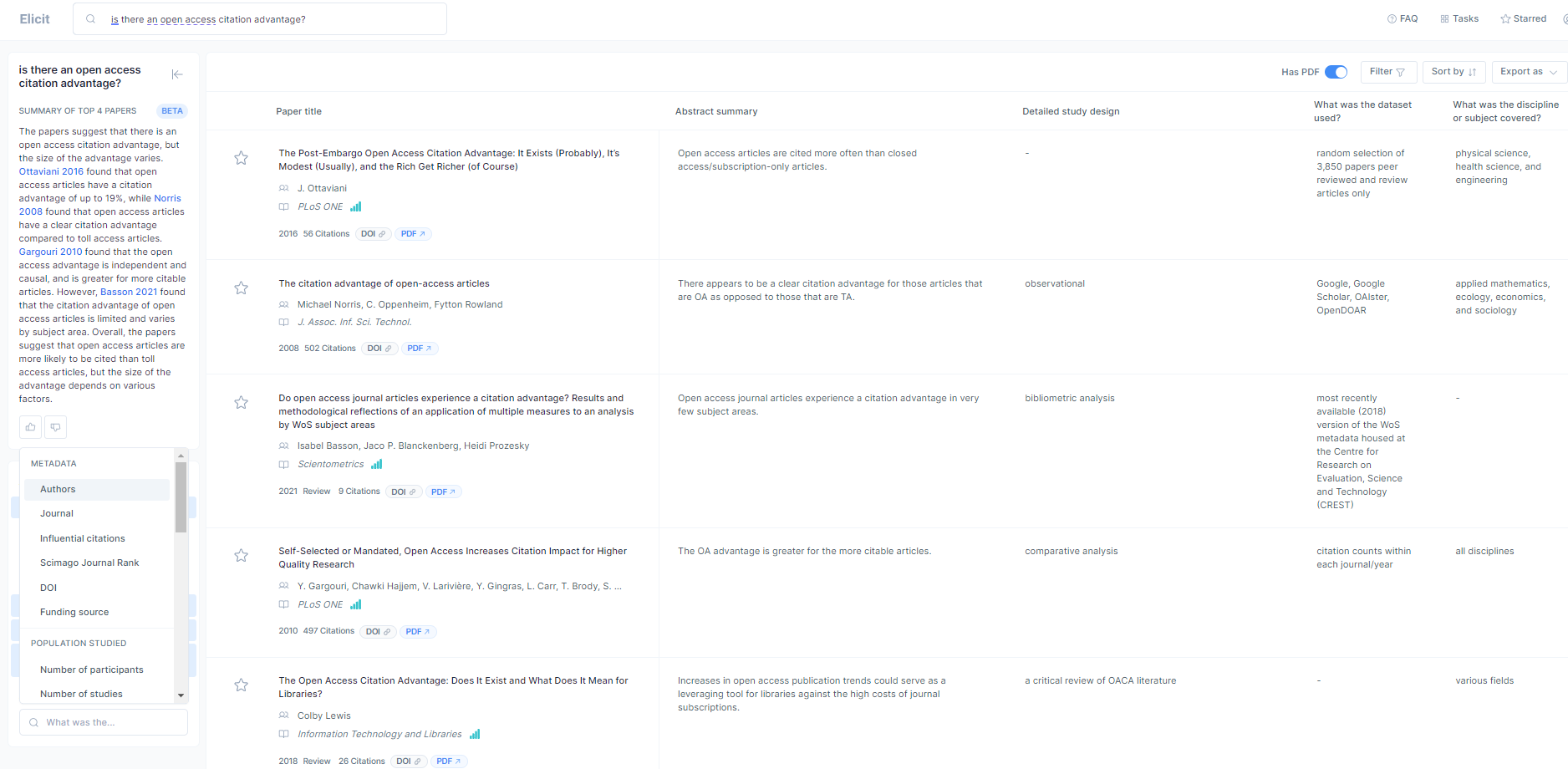
Obviously, these columns could be simple metadata type fields like the year of publication, doi, journal, and authors but more intriguingly, it could extract other characteristics of papers such as but not including:
- Main findings
- Detailed study design
- Region
- Outcomes measured
- Limitations
- Number or age of participants
- Number of studies (useful if you paired it with the filter for systematic reviews or meta-analysis)
- Takeaway suggestions Yes/No (useful if you searched with a yes/no query)
This I personally feel is a killer feature. I use it often to explore the literature to compare similar papers.
You will also notice a few of these characteristics like preregistration, intent to treat, multiple comparisons, intervention, Dose, detection of placebos are slanted towards the support of systematic reviews and meta-analysis and this is indeed one of the targeted use cases.
That said you probably don’t even need to be doing evidence synthesis to benefit from constructing such a table of studies. When I was an undergraduate years ago doing my capstone, my supervisor at the time introduced me to this way of presenting and summarizing multiple studies by creating a table of studies which some call a literature review research matrix of papers. Even today, I hear from many postgraduates this is a common request from their supervisors, as this allows one to quickly grasp the similarities and differences between relevant studies.
But how does Elicit.org figure out details like the limitations or region in which the study was done? Without going into details, a high-level way of understanding is that for each of the top ranked paper, they simply prompt the large language model accordingly with a question.
I say “large language model” rather than name a specific GPT model, because while Elicit.org started off mostly using OpenAI based models, they have slowly moved to using a variety of models including opensource Models and not just OpenAI’s models for different tasks because they are almost as good for a lower cost.
So, for example, when trying to determine the region of each paper they may simply prompt the large language model to ask which region the study was done in and look at the answer generated.
This is of course an oversimplification of how they use language models to determine things, particularly for predefined options. They in fact use a technique they call Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes. Roughly speaking, this means breaking down the steps based on how a human expert would do it, then trying to see if the language model can duplicate each granular step. For example, if a human expert typically looks at a certain part of the methodology section (trial arms) to scan for mentions of placebo in a randomized control trial, they will try to see if Elicit with the language model via prompting or other machine learning technique could do the same steps and adjust accordingly if it failed.
You can even add in columns for new items of interest that are not already predefined. For example, in the screenshot below you can see me create a custom column for dataset used by typing “Dataset used”. Another nice custom column to create is “independent variable”.
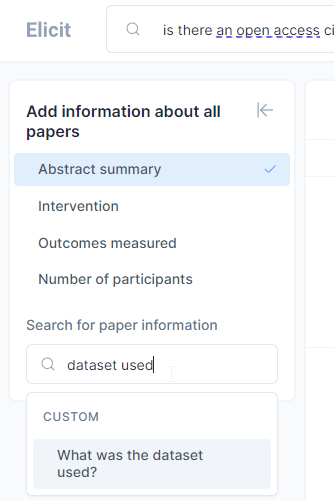
It works pretty well in this use case and the results can be exported as a csv or as BibTex (for import into reference managers).
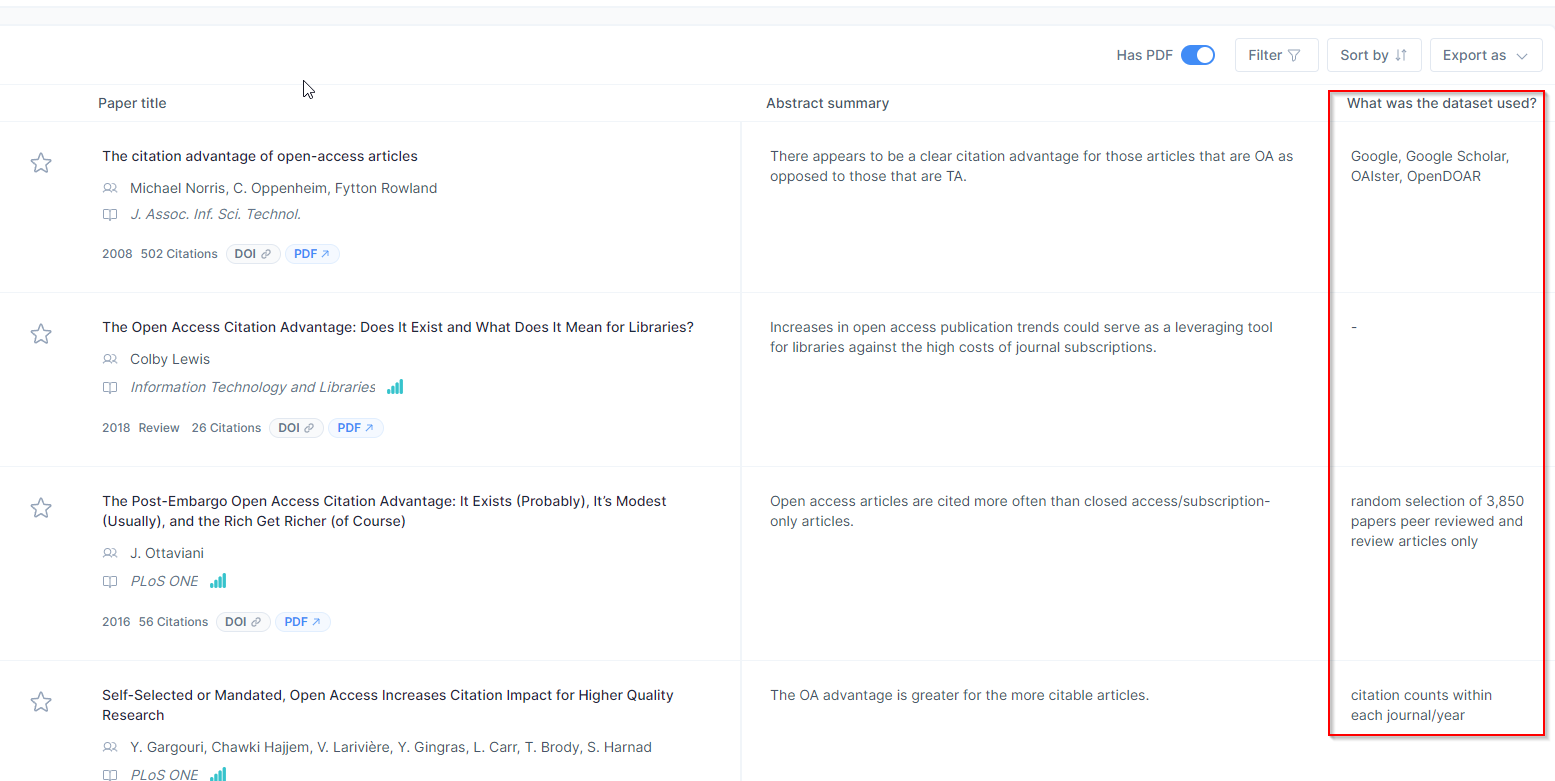
Of course, what information can be extracted from these papers is also heavily dependent on whether Semantic Scholar has full-text of the paper as opposed to just title/abstract etc, so you might want to filter to full-text results only.
What happens if you have already a set of papers found to be relevant and wanted to create the same table? Elicit allows you to upload pdf of papers for it to analyse. Be careful not to upload anything sensitive though.
Again, take the extracted items with caution. Verify the extracted items by clicking on them and checking whether the extraction is correct by verifying over the highlighted text in the paper.
In the example below, I click on an entry that says the paper is using dataset from “Google, Google Scholar, OAISTER, OpenDOAR” and this opens up the article with text highlighted that provides evidence for this.

As quick way to query details of individual papers
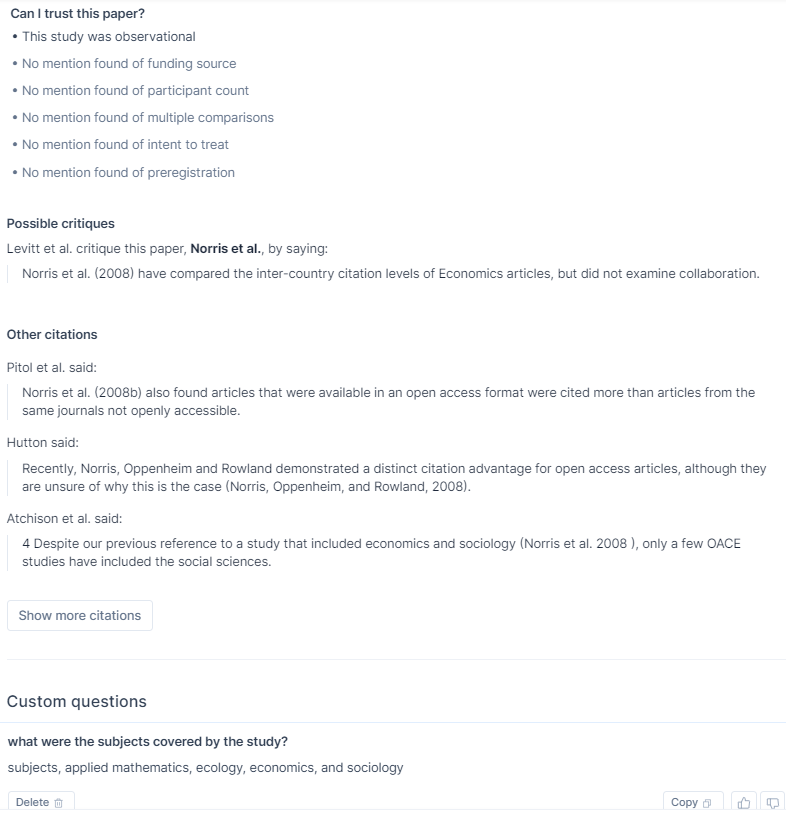
A final feature available is that you can go into each paper and it will automatically generate additional information on the paper, such as looking for possible critiques, looking for various markers of trust and you can always prompt each paper on any specific question you are interested in about the paper.
Conclusion
Elicit.org also has other features such as the brainstorm question feature and in terms of relevancy rankings uses “semantic search” (as opposed to standard lexical search techniques) based on the latest contextual embeddings to match similar words to improve relevancy and more. (See details about ranking algorithm) but I have mainly covered the core features.
It is one of the most impressive new academic search engines I have seen in recent years, and I find myself using it frequently to have a quick look at the available literature.
Though as always you have to be extremely careful about verifying the outputs. We will cover scite assistant, the newly launched “assistant” that uses ChatGPT API in our next issue.
