
By Aaron Tay, Lead, Data Services
In past research radar pieces, we discussed how search engines like Bing Chat, Elicit.org, Scite.ai, scispace are traditional search engines supported with generative AI capabilities.
While Elicit, scite.ai and Scispace are academic search engines, they are all relatively new startups and companies. The question is how or when would the established players in this space such as Elsevier’s Scopus, Clarivate, Web of Science respond?
On Aug 2, 2023 , Nature broke the news that both Elsevier’s Scopus, Digital Sciences’ Dimensions and Clarivate’s Web of Science were launching beta versions of their search engine that incorporate large language models to generate direct answers or summarises to question.
Elsevier and generative AI
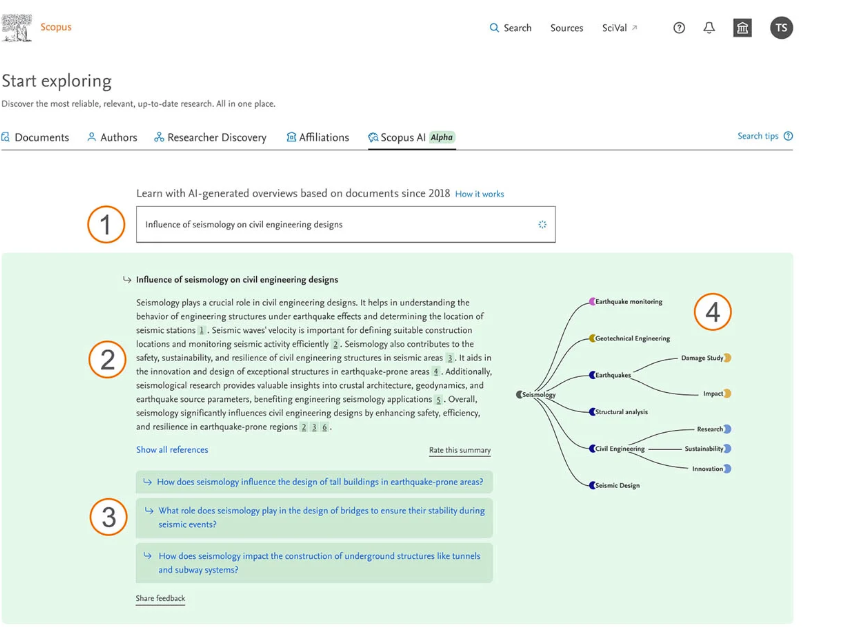
This is how Elsevier puts it.
“Elsevier’s new generative AI provides you with concise, trustworthy AI-based summaries of your queries... Our pilot genAI-powered search model helps you find research papers by query and synthesizes the findings of decades of research into clear digestible summaries, in seconds.”
Similar to earlier examples like Elicit.org, you can search in natural language and get a direct answer with citations.
This new version of Scopus search is still not available except in closed pilot test. Unfortunately, your author has not gotten access to try it yet.
Dimensions AI Assistant
Coincidently, Digital Science’s Dimensions announced a very similar product, Dimensions AI Assistant, also in closed beta testing.
They provide a bit more information stating that the “summaries generated by leveraging the Dimensions dataset and the large language models Dimensions General Sci-Bert and Open AI’s ChatGPT.”
Your author managed to gain access to the tool for some testing. Below shows some of the results.
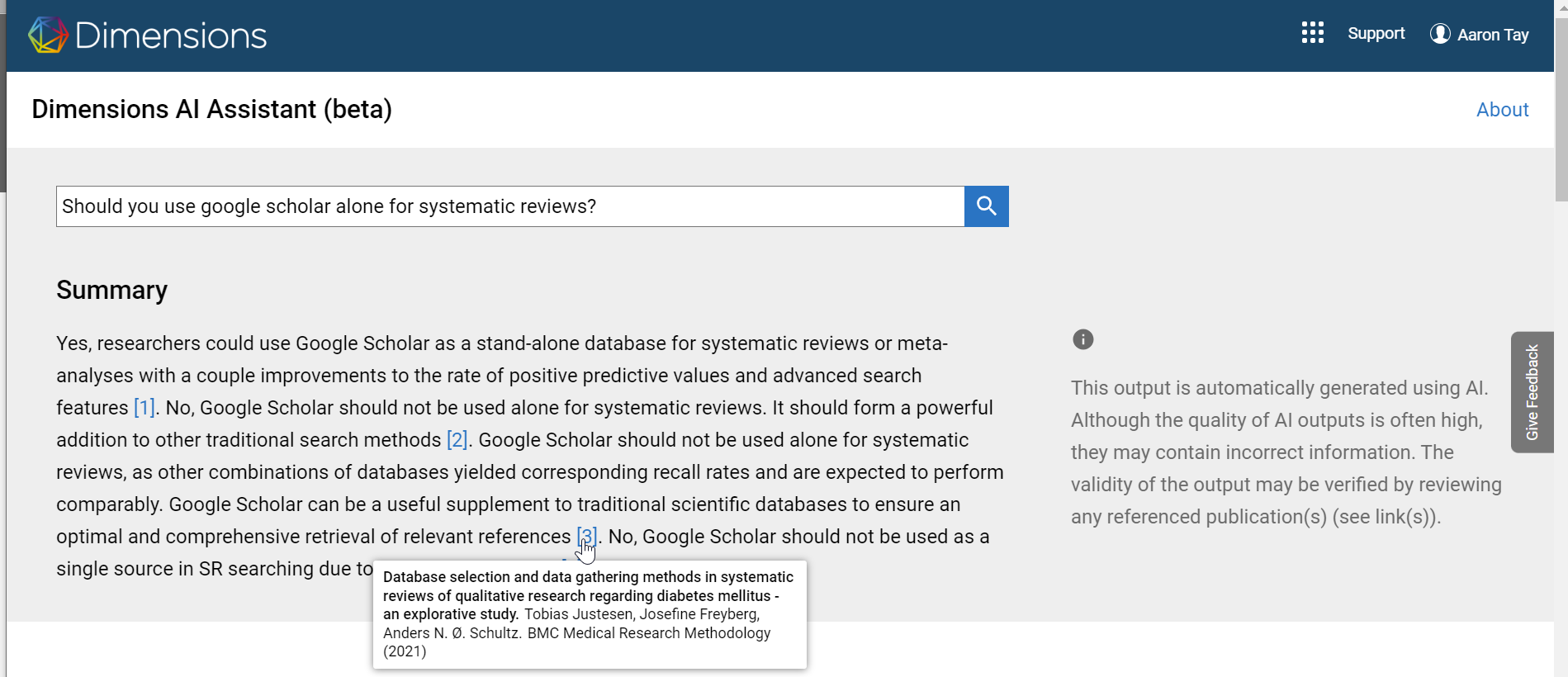
Using one of my standard questions, I find the generated answer has the typical strengths and weaknesses of this new class of systems.
The good thing is for this question at least it does not hallucinate, every generated sentence is supported by a valid citation. Unfortunately, it does not go beyond a simple one line summarize of each paper.
It basically goes, Paper A says yes, Paper B says no, Paper C says no etc. No human researcher would write a literature review like this, most would instead try to compare and contrast these papers and even come up with a final take on the subject.
I suspect to progress further, Large Language Models will have to be taught somehow to mimic the literature writing style of humans, perhaps with clever prompt engineering or through some sort of multi agent debate system to discuss and debate the merits of papers.
The other common use of Large language models in academic search besides generating direct answer is to extract or summarie content from papers to be displayed on the search engine results page.
In Dimensions AI assistant, the direct generated answer is followed by the top 10 results. You can click on “Summary & highlights” which will show a auto-generated TL:DR (too long didn’t read) summary for the paper.
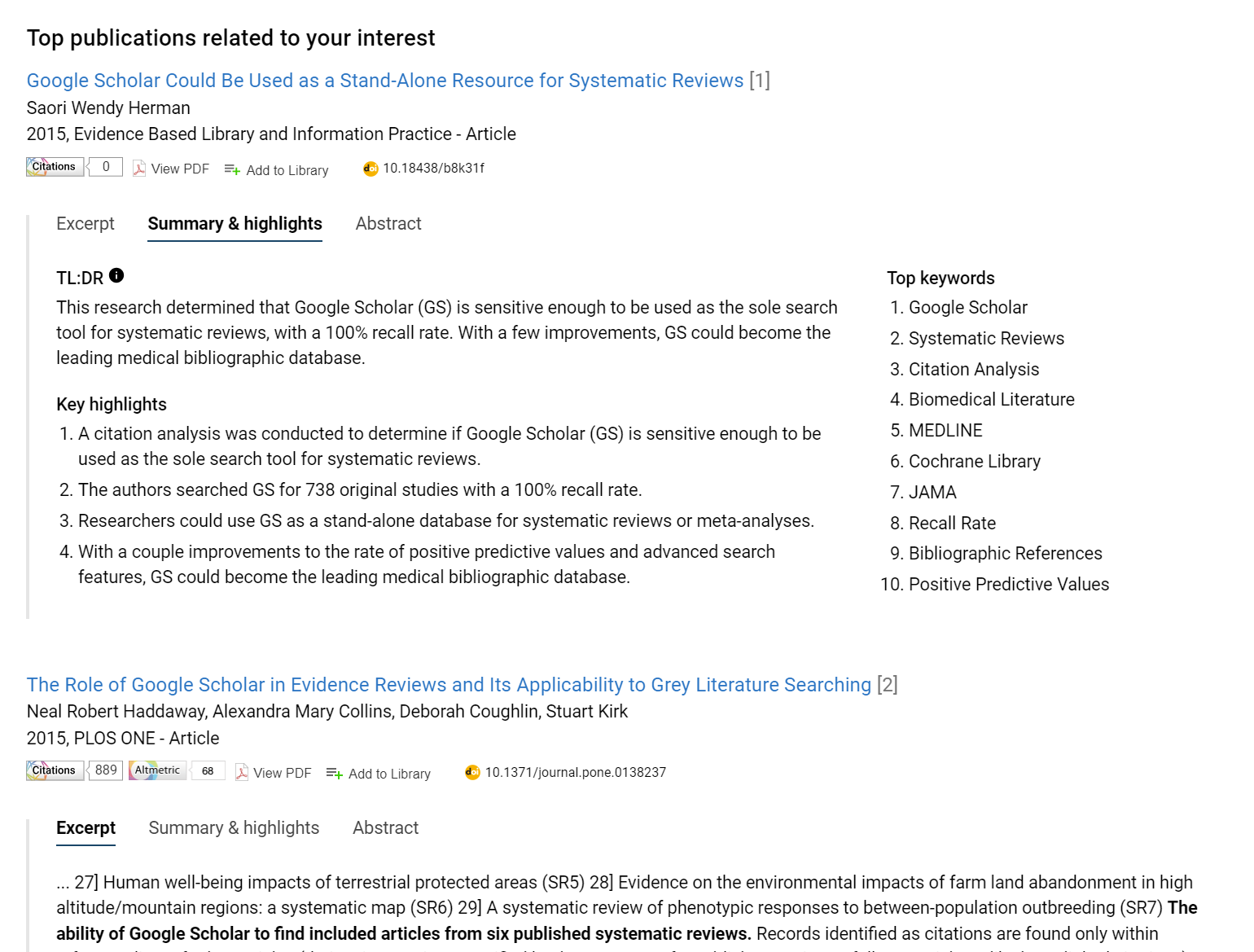
It’s unclear to me if this auto summarise is drawing from full-text or just the abstract. Unlike Scopus, Dimensions does index full-text but it’s unclear if they have chosen to generate summarises from the full-text or just go with abstract. It’s also unclear if they have the rights to use indexed full-text from their content providers in such a way.
Clarivate of Web of Science
As far, as I know while Clarivate has announced a partnership with AI Labs AI21, they have not yet announced any product yet and no screenshots are available at time of writing. I speculate that it seems likely they have something similar as what their competitors are doing in the works.
Conclusion
Although these products are still in early pilots, I currently prefer the results from Elicit.org as the generated answers seem more refined.
One big question on my mind is also how useful are such generated answers? Currently, they tend to provide very generic answers which are only helpful if you don’t know anything about the field (and if you are that new, you must be careful about hallucinations).
Part of the reason why the answers seem generic is because they currently mostly leverage only on title, abstract and not full-text. If you ask very specific questions, it is unlikely to answer with very specific details. Of course, besides the technical challenges , accessing full-text of papers runs into a host of unanswered copyright questions...
