
By Aaron Tay, Lead, Data Services
Thinking of joining the Generate Your L(AI)rary Hackathon on the use of generative AI for library and research applications but looking for ideas? This article may help...
1. Building Library and Research Chatbots
Chatbots are nothing new, but the latest generation of Large Language Models e.g., BERT, GPT3, provide unsurpassed levels of Natural Language Understanding and Natural Language Generation leading to chatbots that are far more fluent and better at understanding chat queries.
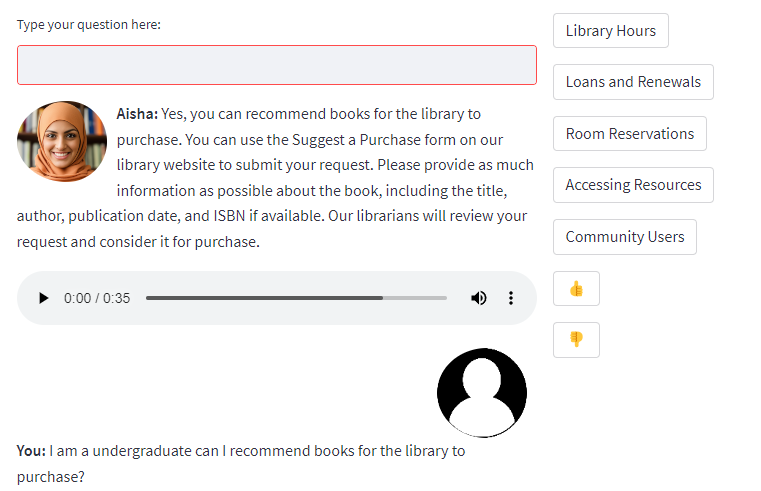
Full technical details are reported in the article Aisha: A Custom AI Library Chatbot Using the ChatGPT API, but Aisha is an early stage basic chatbot prototype that involves at the high level the following steps:
- Preparing relevant data by scraping and extracting URLs from the Libraries' homepage and LibGuides
- Converting the content from these urls into embedding using OpenAI’s embedding model (text-embedding-ada-002)
- Storing the embeddings in a vector database, they use Chroma
- As the user types into the chat bot, the text input will be converted into embeddings using the same API model and these embeddings will be compared against stored embeddings from the database (using the cosine rule) to find the most “similar” text.
- The top few embeddings that are most similar will be added as context and the Language model (ChatGPT-3.5-turbo) will be prompted to answer the question with the context included.
- They were initially inspired by this sample Python script from the OpenAI cookbook but further modified it to store the embeddings in a vector database. They also utilize the Langchain framework to make it easier to work with language models, including build support with the vector database Chroma
- The web interface itself was created using the popular Streamlit Python library
For more details, read the paper.
We are also aware of a SMU chatbot implementation called SMU Chad Bot by SMU Undergraduate - Joen Tan. The code is available on Github and states that the chatbot
is built with a custom knowledge base of common Singapore Management University (SMU) FAQs to assist students in their daily activities. FAQs are scraped from various SMU-affiliate sites such as SMU Blog & SMU's main site.
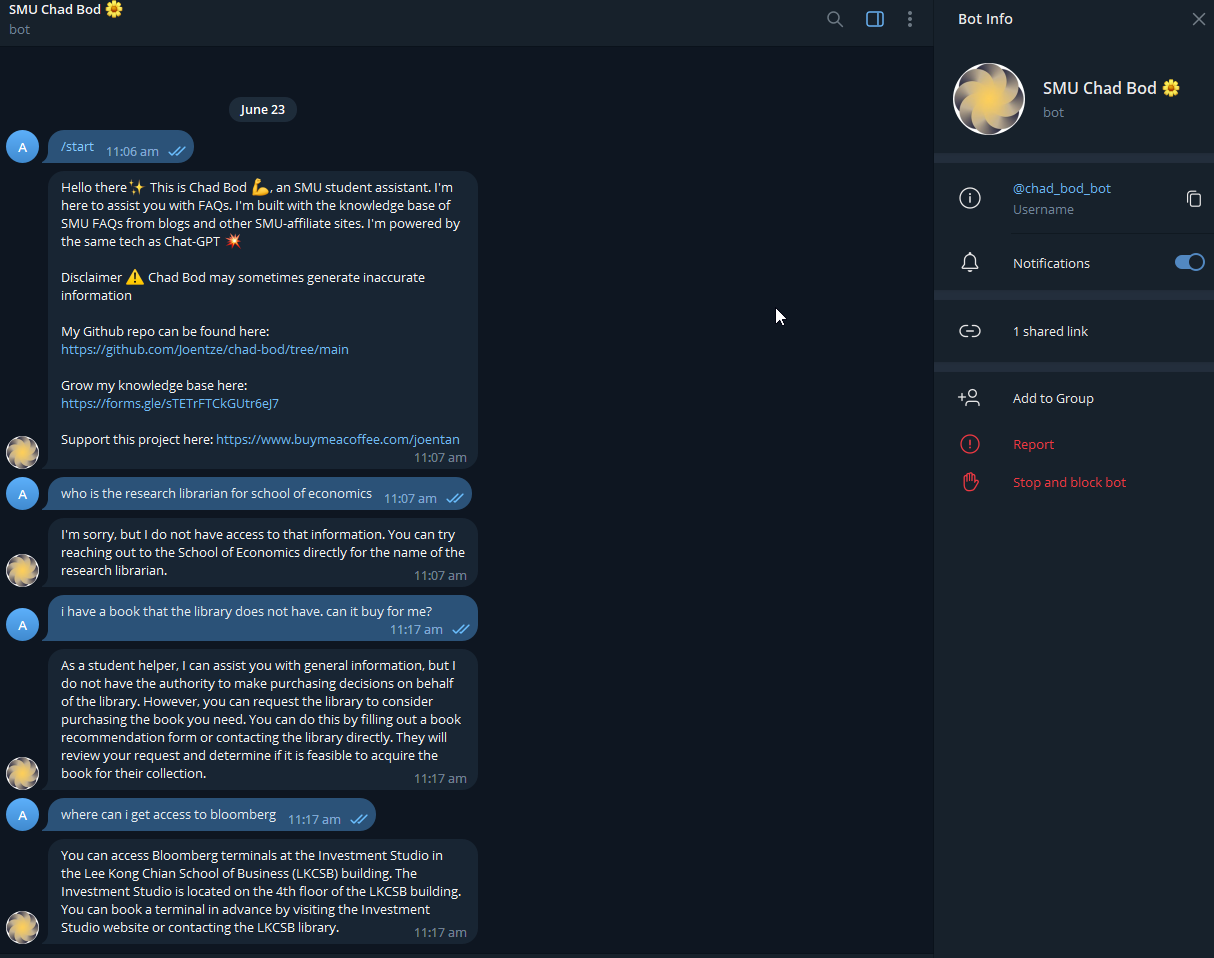
Under the hood, the bot works similarly even though it is not designed specifically to support the library as its database is not populated with a lot of library related content and the interface is made available telegram.
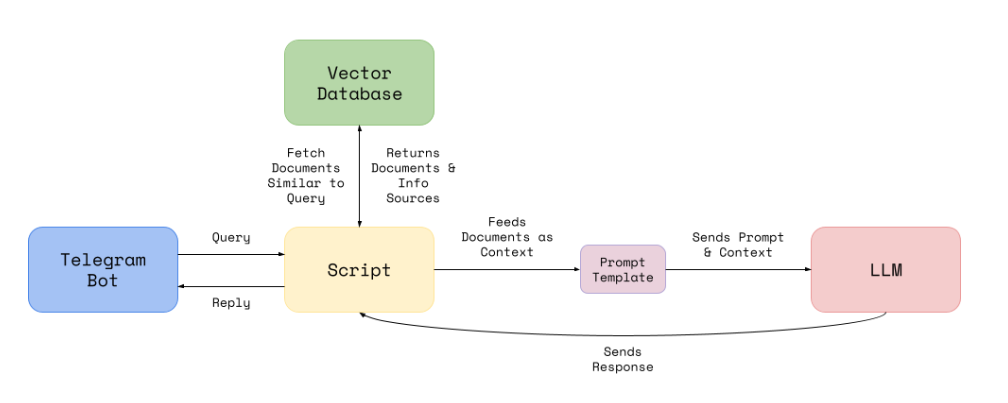
Both these chatbots are early examples of what is possible using current state of art Large Language models and there are many limitations that might be improved upon.
2. Building ChatGPT plugins both for https://chat.openai.com/ and via API
It is well known that if you use the native ChatGPT from https://chat.openai.com/, its knowledge base is limited to up to Sept 2021 which is the data it was last trained to. For example, ChatGPT does not know who won the last FIFA world cup.
One solution is to fine-tune the model with specialized information, but this is quite expensive to do and at the time of writing, it is not offered for the latest GPT-4 and the more well-known ChatGPT-3.5 Turbo model.
ChatGPT plugins solve this issue as they allow you to query data sources including the web in real-time when needed to retrieve needed information. For example, many libraries including ours at SMU Libraries store library hours in a system called LibCal. and the data is available via an API.
Similarly, plugins can allow the chatbot to retrieve data from systems that are not open or behind paywall. For instance, using Exlibris’s Primo and Alma API, you might be able to obtain information about the availability of books, articles from SMU Libraries or even check for fines. Plugins could be created to use databases that have APIs for use (e.g., Scopus or Web of Science).
Instructions on how to build your own Chatgpt plugins are available, but it essentially requires you to be aware of what APIs are available for use. The library is compiling a list of APIs that could potentially be used to support library and research functions (see next section) but feel free to reach out to ask me for suitable APIs, if you have functionality in mind that you are looking for.
A similar approach can be taken to improve the chatbots above.
Take Aisha, the above-mentioned prototype chatbot which has no real-time access to the information on the web. For example, when asked about opening hours, it may answer with outdated information if the vector database isn’t refreshed sufficiently frequently with the latest changes.
Up to recently, there was no official way to support plugins using the API but June 13’s announcement of the support of “Function calling” in the latest GPT-4 and ChatGPT-Turbo models are more able to “more reliably connect GPT's capabilities with external tools and APIs” as they are better tuned to know when to call a function and to respond with the appropriate JSON output.
3. “AI search and recommender”
There are a couple of ways to combine search with LLMs like OpenAI’s GPT models. In earlier research radar pieces, we talked about “retrieval augmented Large language models” like Bing Chat, and academic versions like Elicit.org and Scite.ai Assistant.
What search engine should you use to blend its results with LLMs? The following academic sources include APIs that can be considered.
- OpenAlex (Largest source of metadata including citations – free access)
- Core (Largest source of metadata and Open Access full-text – free access, needs to register)
- Scopus (Metadata and citations used for many University rankings, Commercial, access is available via SMU community- check with the library for access)
- Primo and Alma API (Commercial, allows access to results from SMU Libraries Search and user accounts for loans checking etc – check with the Libraries for access)
Perhaps the easiest way to implement this is via a ChatGPT plugin (see above)
LibraryThing also recently launched its own take on combining ChatGPT and search (currently launched as https://www.talpa.ai/) which serves as a basic recommender.
More accurately it claims to be good at “What’s that book” questions.
Below, I search for a book with a vaguely remembered plot and it correctly suggests Ender’s game.
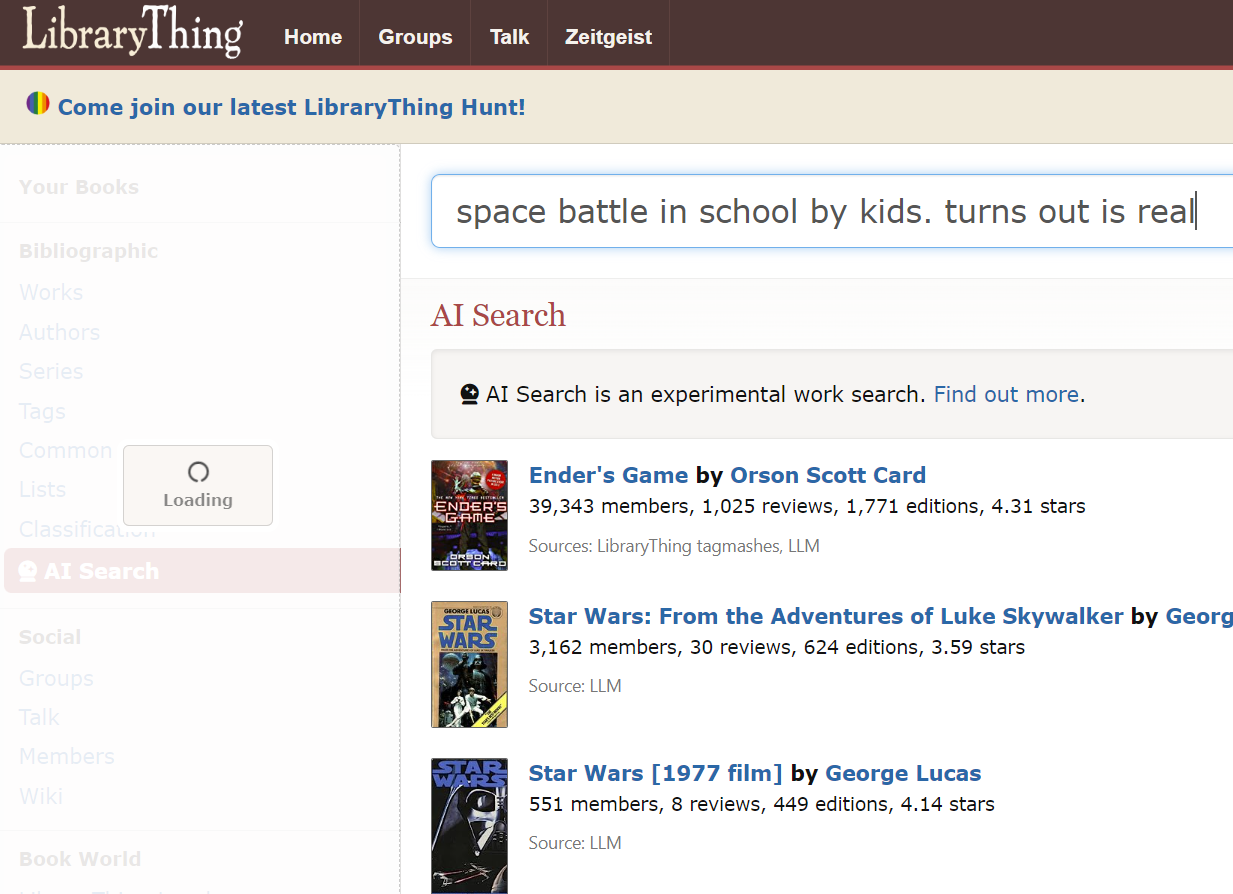
- Query the OpenAI or alternative large language model API with the user query and ask for a response in JSON (with no explanation).
- To ensure it doesn’t make up books, the json output is matched against LibraryThing data to verify the book suggested is real.
Supposedly the API will occasionally produce non-JSON output, but with the latest update this should be less of a problem.
Of course, there is potential for these technologies to do personalized recommendations (BookGPT?), and there is a rising amount of research studying this (see here, here, here for example)
Conclusion
These are just some possibilities on how you can incorporate the capabilities of the latest AI into library and research use cases.
Some other ideas include using ChatGPT
- to extract and summarize useful information from articles
- to classify and label data
- To detect anomalies in the data
- To improve productivity
Of course, the elephant in the room – is the problem of “hallucination”, and the success of any application depends on how well the idea can guard against this issue.