
By Aaron Tay, Lead, Data Services
JSTOR by Ithaka is a popular and well-loved academic database covering a variety of disciplines though with core strengths in humanities and social sciences. Like many academic content owners, they have been experimenting with the use of Generative AI (typically implemented with large language models) to improve their service.
Your author was invited to join the beta earlier in October and this is my short introduction and thoughts about it so far as of early December 2023.
A too “long didn’t read” summary is that this JSTOR beta brings together many interesting ideas though the quality of implementation needs to be tested.
Of course, this is just a beta and things change quickly but if you are interested in seeing how generative AI may integrate with an academic search of a typical database, do read on.
JSTOR generative Ai features lack multiple document retrieval + direct answer (as of December 2023)
The first thing I noticed about using the beta was what was NOT included. Currently, the most common type of Generative AI feature implemented with search is a technique known as RAG (Retrieval Augmented Generation). In a typical implementation, a user query would be answered by first doing a multi-document search to retrieve relevant text segments which is then fed to the generative AI language model to generate a response.
The advantage of such a system is that not only is the answer grounded in a real piece of information but also a specific reference can be generated for the user to verify the answer.
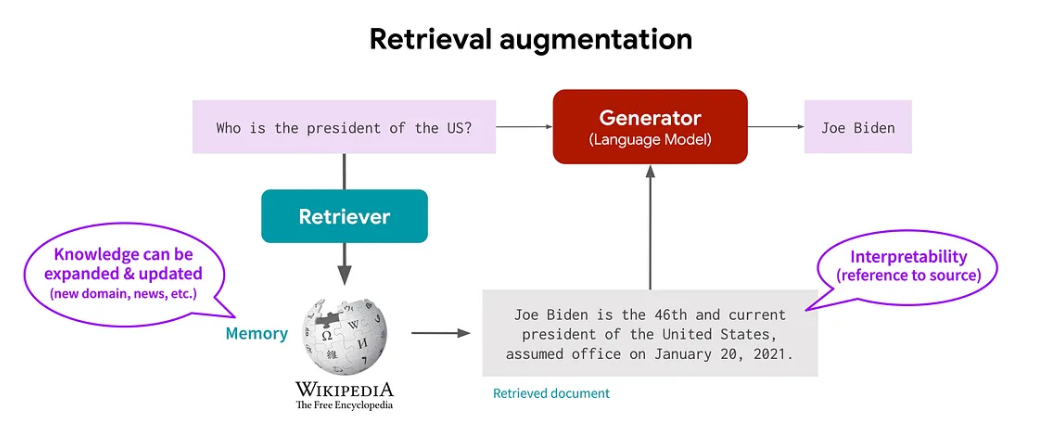
The shift in search engines, moving away from presenting potentially relevant documents to directly providing answers akin to Q&A systems, is undoubtedly noteworthy and potentially paradigm-shifting. Some also refer to this feature as "conversational search" and this has been a key focus for numerous search engines delving into generative AI.
Currently, general search engines such as Bing Chat, Perplexity.ai, Bard, and the newly launched Google Search Generative Experience, along with academic search engines like Elicit.com, Scite.ai Assistant, Scispace, Scopus (in closed beta), Dimensions (in closed beta), and Exlibris Primo (in closed beta), all have this feature.
Below is an example from the beta Scopus AI.
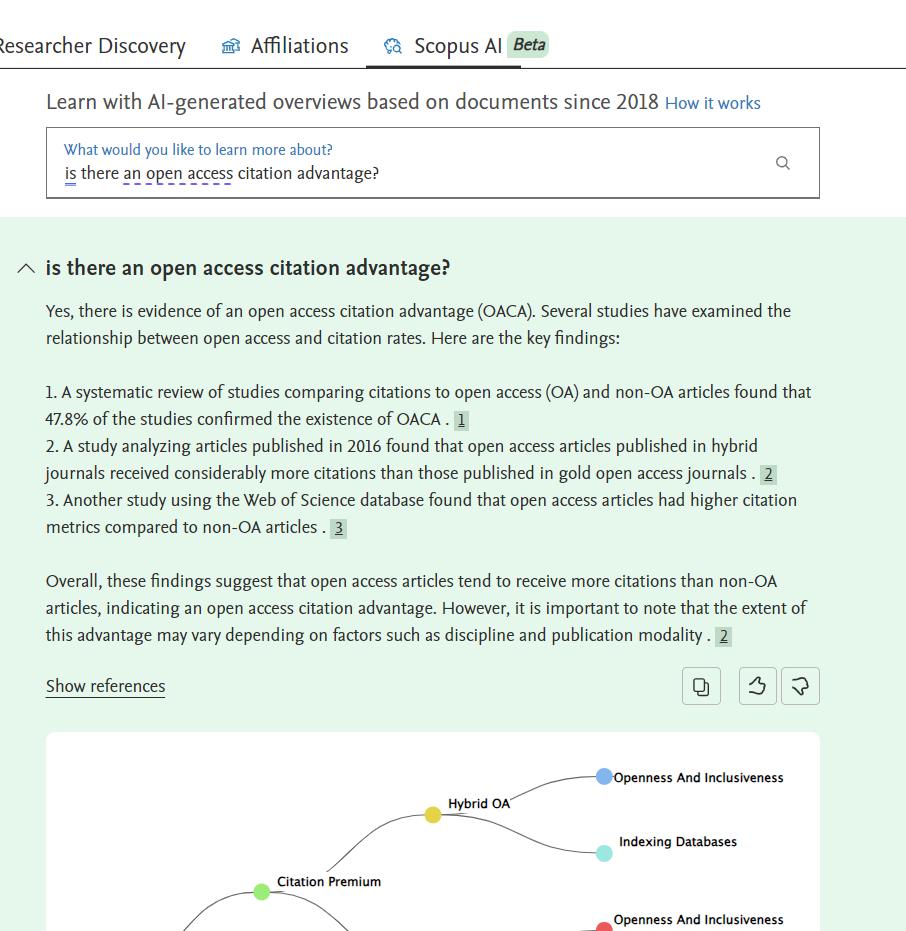
So, it is a surprise that this feature is not included in the beta as of 1 December 2023, though as you will see the RAG technique is used on individual document level to extract answers.
JSTOR beta offers a new experimental search – Semantic Search?
While JSTOR beta shows a traditional search result page, they also offer a new type of search under “experimental results”.
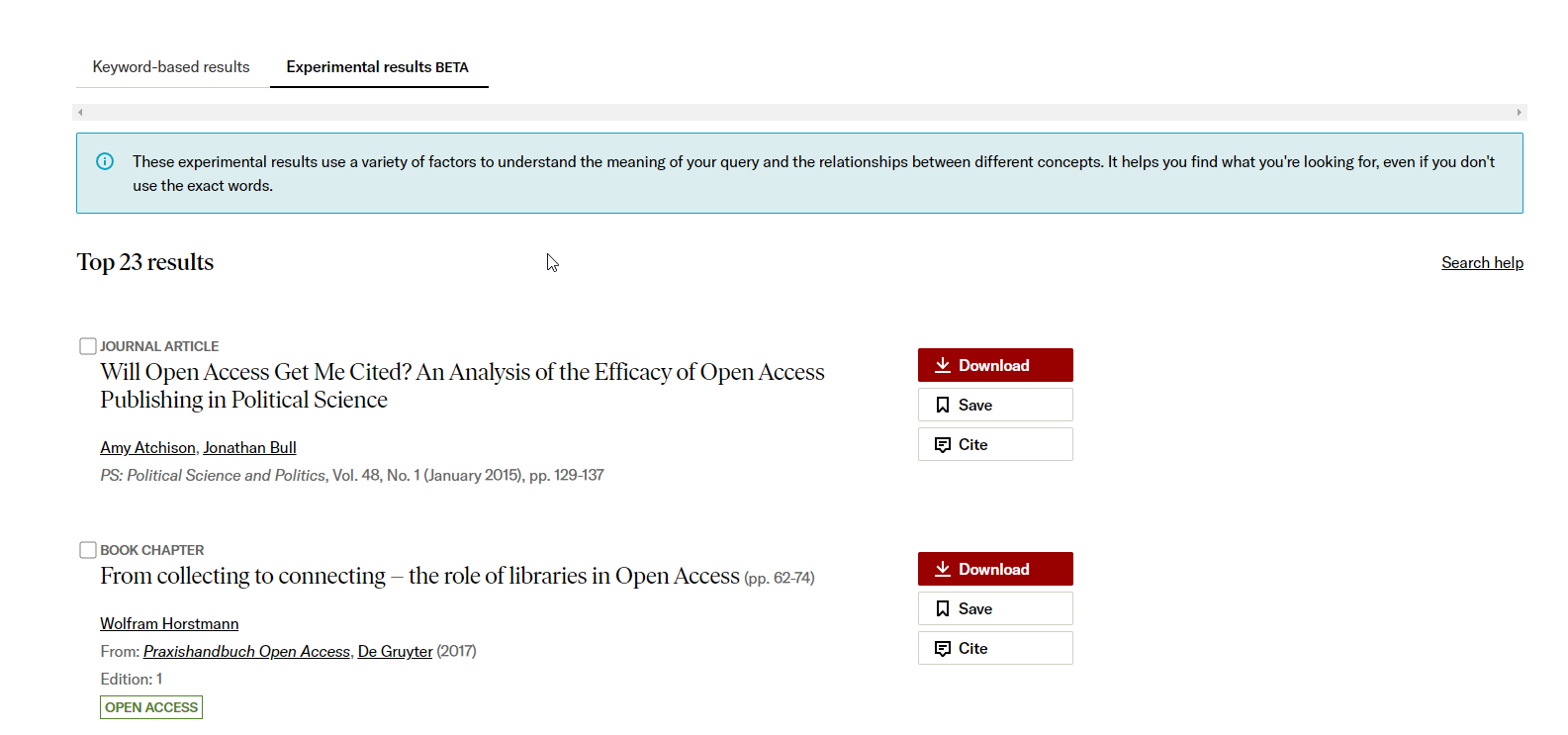
Looking at the description, this new experimental search
uses a variety of factors to understand the meaning of your query and the relationships between your concepts. It helps you find what you are looking for even if you do not use the exact words.
In other words, this search uses semantic search instead of the standard keyword or lexical search.
While standard lexical or keyword search matching often uses techniques like stemming/ lemmatisation and query expansion to try to improve the recall of results, it is still fundamentally operating word by word. Semantic search goes beyond, typically using state of art contextual embeddings for finding documents that are relevant or similar to the query. State of art embeddings currently used for search and reranking are obtained from Transformer models such as BERT models and more recently autoregressive GPT type models like OpenAI’s ada002 embeddings.
Semantic search is not new and has been touted for years but typically with poor results. However, given the success of Large Language Models like OpenAI’s ChatGPT model that seem to understand your prompts even with typos, it seems natural to think semantic search might be worth trying. How does this experimental search perform versus the more traditional key-based search?
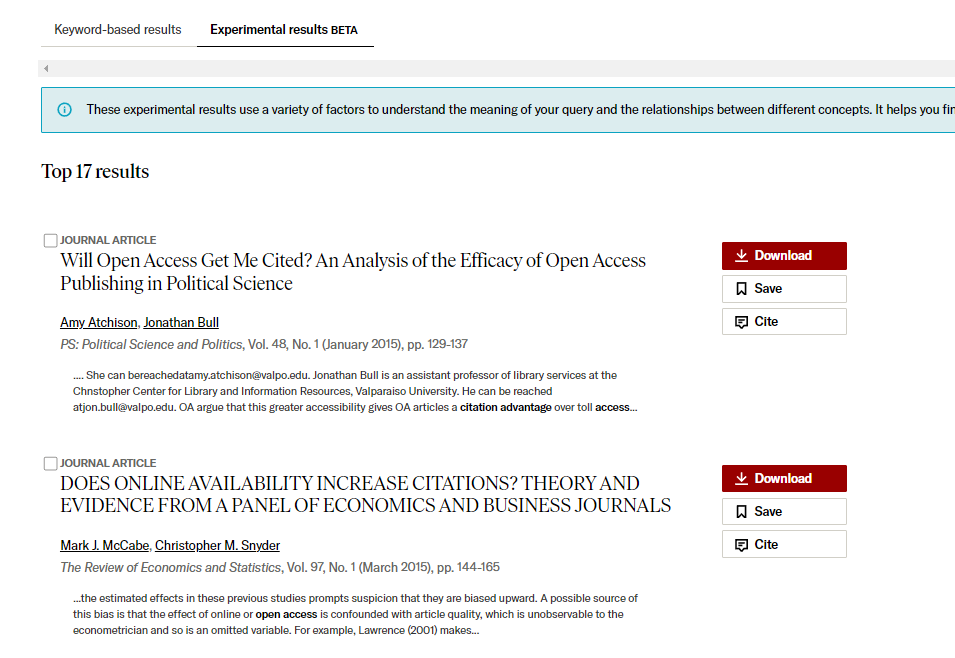
I have not had the chance to do a full-blown comparison but so far, anecdotally the results look good. Take the following query where I searched for
Open access citation advantage
Which is a hypothesized advantage of publishing papers open access leading to higher citations
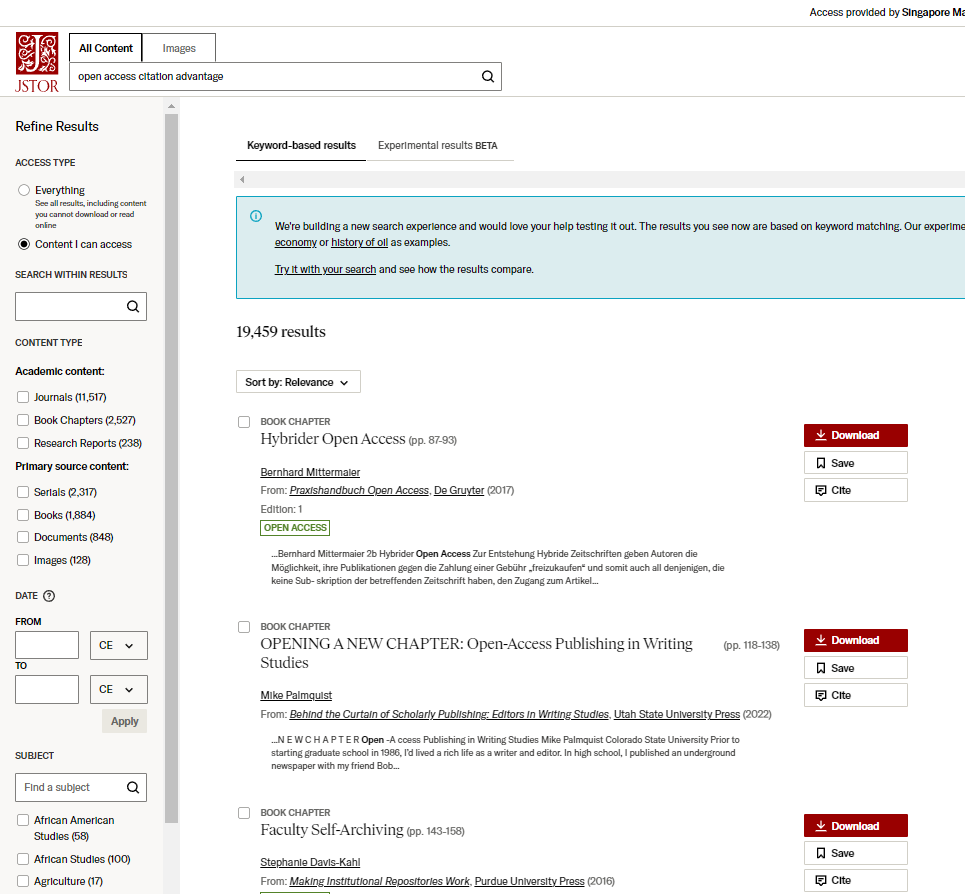
Sadly, the default keyword-based search does badly where only the #8 and possibly #10 results are relevant. The exact search using the experimental search has a relevant hit on the first result.
! The #6 paper is relevant too.
I did not expect this search to be a difficult query (as there are a lot of studies in this area), but it is instructive to see how keyword search can fail, for example, the #1 result in the keyword search is due to matching the query terms in the title of a reference!
My limited personal experiment, which involved about five queries on both search platforms, indicates a consistent pattern, with the new experimental search generally yielding better results, especially for the top-ranked item, while the traditional keyword search falls short. However, further testing is necessary for a comprehensive assessment.
Another one I tried where the traditional keyword search totally failed but the experimental search did much better was
Can you use google scholar alone for systematic review
Search with keywords or in natural language?
An interesting question I wondered is if I should type in natural language. For example, instead of searching with just keywords - open access citation advantage,, should I instead search for
Is there an open access citation advantage?
Interestingly, the search results remained the same for the keyword search, but the results from the new experimental search came back with the top two results being relevant!
In the case of the default keyword search, most of the additional words are probably ignored as stop words as such the results remain unaltered.
However, with semantic search, all words matter, and state of art semantic search can take into account the order of words and “understand the query” even if it is a phrase that is mostly stop words like “Is there an....”
For example, in 2019 when Google integrated the BERT model (a state-of-the-art language model used for semantic search) into Google, they noted that the power of BERT came from a breakthrough that
was the result of Google research on transformers models that process words in relation to all the other words in a sentence, rather than one-by-one in order. BERT models can therefore consider the full context of a word by looking at the words that come before and after it—particularly useful for understanding the intent behind search queries.
They claimed that because of this, Google could now account for the word “to” in queries like
“2019 Brazil traveller to USA need a visa.”
and boost the ranking of pages related to travel from Brazil to the USA instead of the other way around.
Even if semantic search (or a hybrid of it and keyword search) is shown to be superior at relevancy ranking and this is far from proven especially across diverse domains, there are several drawbacks.
Semantic search is much less predictable than keyword search. It’s not only better at surfacing and ranking papers that were already found by keyword search (but ranked low), but it could easily find relevant documents that do not have all the keywords in the query because it is looking at semantics (or meaning) rather than just lexical keyword features.
Another interesting quirk of many semantic search systems (and some non-Boolean lexical keyword systems) is that you can type in a long search query with many keywords, and it will always find some document that is the closest in meaning rather than show no result.
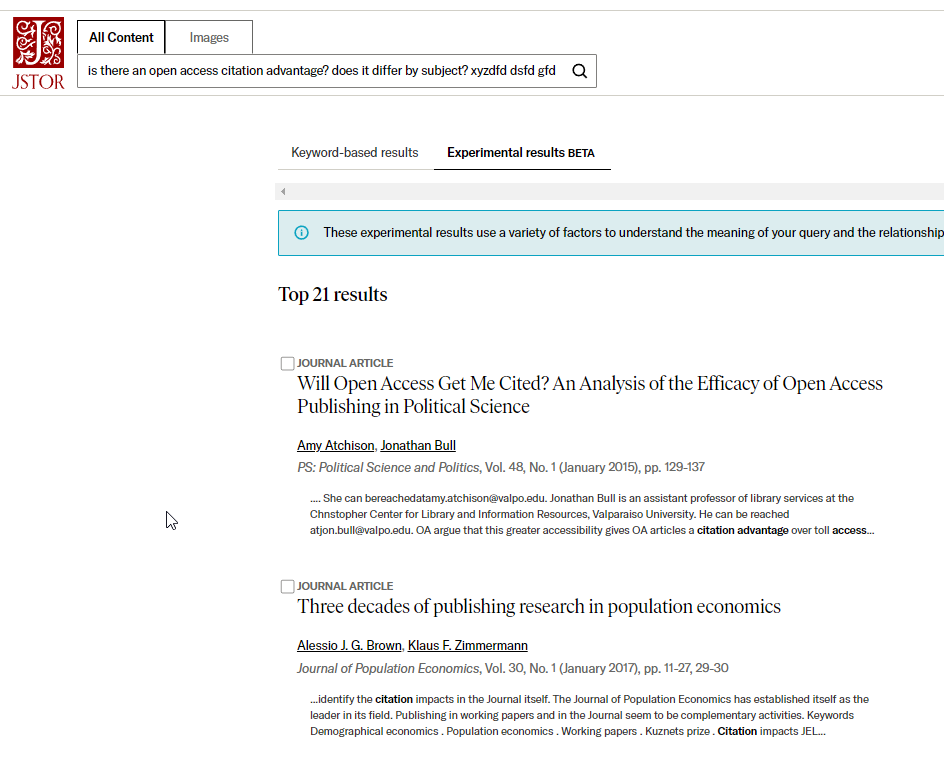
This appears to be true for the JSTOR experimental search. For example, if you try a query with nonsensical keywords
Is there an open access citation advantage? Does it differ by subject? xyzdfd dsfd gfdgds gvdfgv
The traditional keyword-based search will show no matches.

However, the new experimental search still shows some matches!
Using generative AI to explain search context and summarise
When you use keyword matching, it is usually fairly easy to understand why a document is surfaced and to evaluate if it is what you want. Typically, you can just look at the highlighted terms in the search context shown on the search engine result page or go to the document and press Clt-F to search the document and see the parts of the document that match the query keywords (stemming results in different variant forms beings and even synonyms being matched complicate matters only a little more).
But when semantic search comes into play, things get even more complicated. Semantic search has the capability to match documents that may not include all or any elements of the search query, making it difficult to immediately determine if the document is relevant.
Also, as mentioned earlier, many semantic searches will try to give you some results, even if none are relevant. How does one tell without reading the paper?
JSTOR’s brilliant idea is to just call the generative AI to answer that question! This is RAG (Retrieval augmented generation) applied to single documents. When you click through from any search result (both traditional keyword search and the new experimental results tab) to the document result, it will eventually prompt the generative AI to answer the following question (from the full text of the document)
How is < query > related to this text?
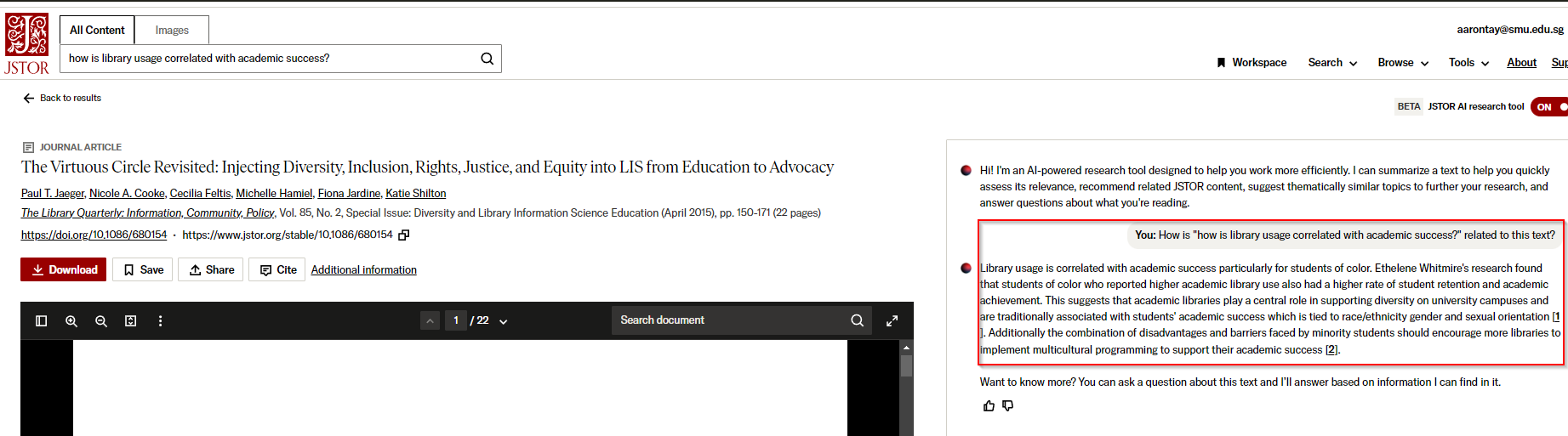
In my first example above, it says the document is relevant to the query.
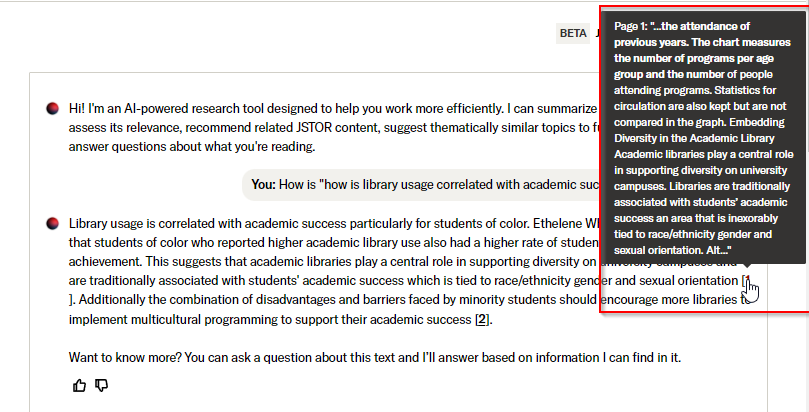
But like any typical RAG system, you do not have to take what it says on faith, you can check the citation, mouse over it and see the text in the document it found to justify what was generated.
Below shows an example of looking at the text supporting the generated sentence
This suggests that academic libraries play a central role in supporting diversity on university campuses and are traditionally associated with students' academic success which is tied to race/ethnicity gender and sexual orientation [1].
Still, it seems to be reasonable, and I notice it is often very willing to say the document has nothing to do with the search context as shown below.
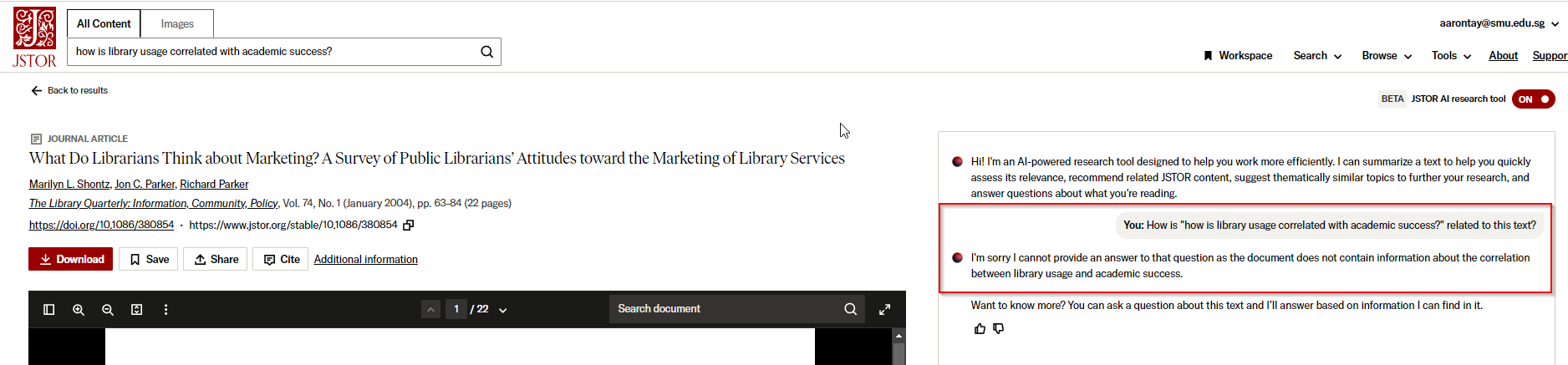
It is interesting when you realise that the document retrieved above was the second-highest ranked relevant result using the traditional keyword search method. However, upon clicking into the document, the generative AI acknowledges that, despite its high rank, the document has no relevance to the query.
It also occurs to me that it is easier to verify when the generative AI assistant confirms a document is related to the search query. However, in the case of a negative assertion by the generative AI assistant, it is more challenging to verify a false negative without thoroughly scanning the entire paper.
JSTOR generative AI features for for discovery and quick comprehension
Like many similar systems implementing RAG over individual articles (e.g., Elicit, Scispace), you can ask arbitrary questions, but it is interesting to see the other default prompts JSTOR provides.
According to JSTOR’s blog post on generative AI , there are prompts that are for “Discovering new paths for exploration”:
- Recommend Topics
- Show me related content
Below shows some screen captures for both prompts.
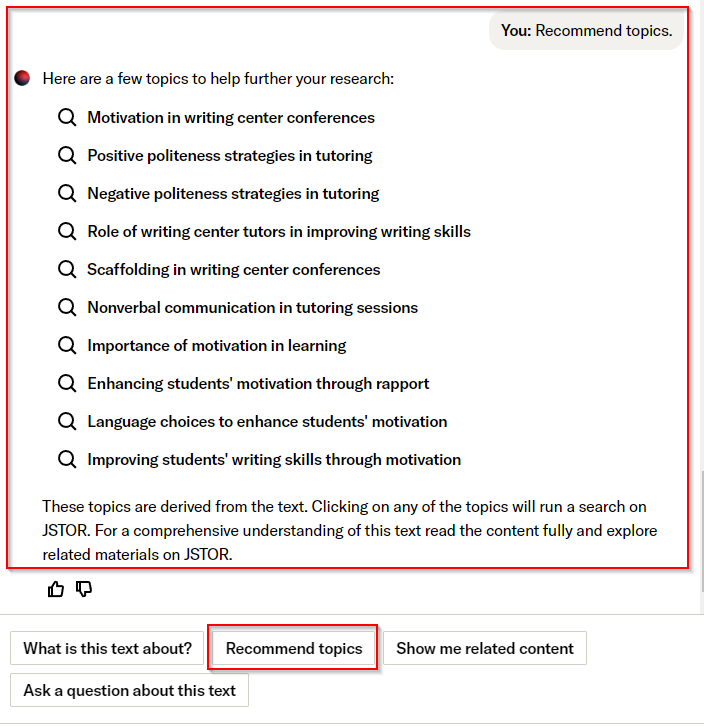

The other major set of prompts relate to quick comprehension of text
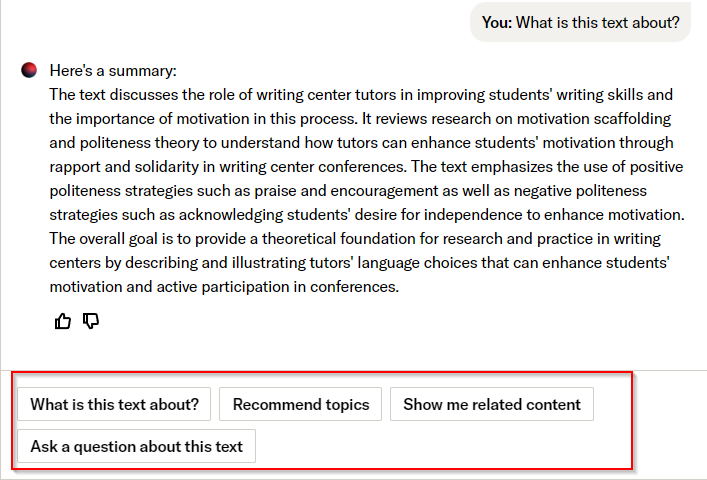
- What is the text about
- Any arbitrary question you can ask
Below shows a screen cap after prompting “what is the text about”
Accuracy of generative AI in JSTOR
Retrieval augmented generation is not a magic bullet. Even in the case of JSTOR, where RAG is used at the individual document level to summarise or extract information, accuracy is not 100%.
RAG technique has the virtue of putting in a citation so you can verify if the citation is correct, for example, if the auto-summary says a paper is on X and you do not trust the system you can verify the citation. However, if the system says a paper isn’t on X, it is much harder for humans to check for false negatives.
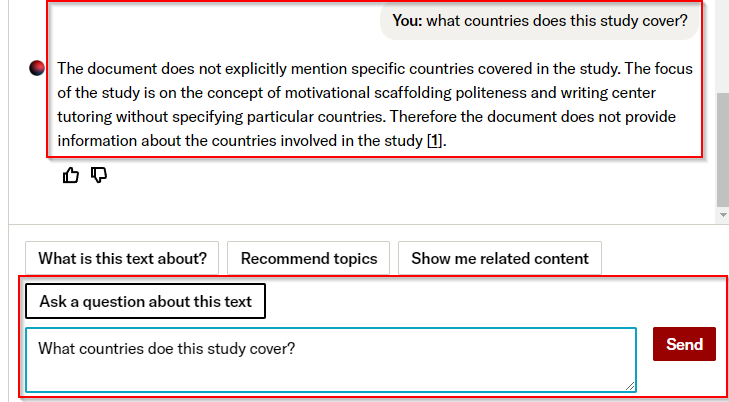
For more information on what these prompts are designed to accomplish, refer to the blog post on the subject.
Conclusion
We are very early in JSTOR’s (and academic search in general) exploration of the features generative AI that might be useful.
To learn more, refer to the following official links: